
About GEO DataSets
Background
The GEO DataSets database stores original submitter-supplied records (Series, Samples and Platforms) as well as curated DataSets. See the Overview for information about these different records types and how they are are related to each other.
Curated DataSets form the basis of GEO's advanced data display and analysis features, including tools to identify differences in gene expression levels and cluster heatmaps. GEO Profiles are derived from GEO DataSets. Not all original submitter-supplied records have been assembled into curated DataSets yet.
The GEO DataSets database can be searched using many different attributes including keywords, organism, DataSet type and authors. Examples and full details about how to search for GEO DataSets of interest are provided in the Querying GEO DataSets and GEO Profiles page.
Information about how to interpret GEO DataSets results pages and how to use the Data Analysis Tools is provided within the following annotated screenshots.
GEO DataSets Results Page
Consult the table below for information about how to use and interpret GEO DataSet results pages.
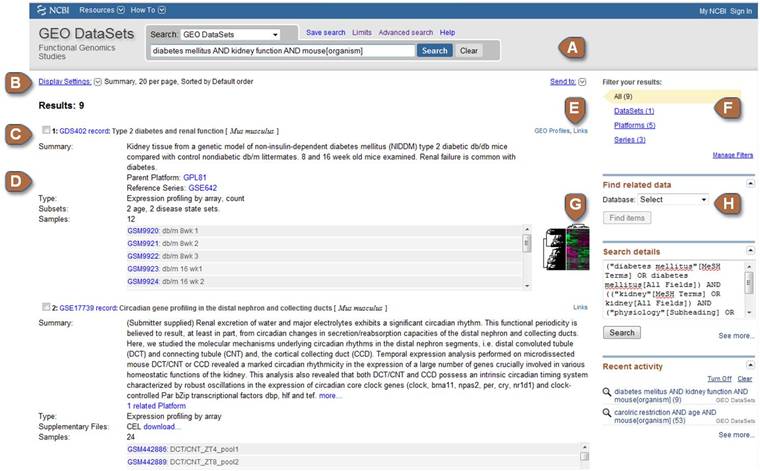
| A | Search box | Identify GEO DataSets of interest by entering keywords or a search statement into this box. Various terms can be used in the search, including keywords, organism, DataSet type and authors. Examples and full details about how to construct search statements are provided in the Querying GEO DataSets and GEO Profiles page. Search results can be saved in your My NCBI account using the Collections feature. The Advanced Search page provides user-friendly tools to help construct complex queries. |
|---|---|---|
| B | Display Settings and Send to | Use Display Settings to change the display format or the number of items to display. Use Send to to export the results as a plain text File, or save the results to the Clipboard or your My NCBI Collections. |
| C | Title line | Lists the DataSet (GDS), Series (GSE) or Platform (GPL) accession number, followed by title and organism. |
| D | Summary, Type, Subsets, Supplementary Files and Samples |
Summary: A summary description of the DataSet, Series or Platform record. Type: The DataSet or Series type. Types indicate the general application (e.g., expression profiling) as well as the technology (e.g., high-throughput sequencing). DataSets records also display the Sample Value Type. Subsets: A summary of the number and type of experimental variable subsets represented in the DataSet. Supplementary Files: Indicates the types of supplementary files that were supplied with the original submission. Supplementary files usually refer to native raw data files, e.g., Affymetrix CEL files. Samples: States the number of Samples in the DataSet or Series, and lists the Sample accessions numbers (GSM) and titles. |
| E | GEO Profiles and Links | Reciprocal links to relevant records in other NCBI databases including PubMed, Epigenomics and SRA. Links to corresponding GEO Profiles are provided on DataSets. Links can also be retrieved in batch mode, see Find related data section below. |
| F | Filter your results | Lists the number of DataSet, Series and Platform records retrieved by your query. Click to restrict your retrievals to a specific record type. |
| G | Thumbnail cluster image | Clusters are provided on DataSets. Click the image to be directed to the DataSet record with contains several data analysis tools, including clusters heatmaps, see Cluster heatmaps section below. |
| H | Find related data | This feature is similar to that described in the GEO Profiles and Links section above, but in batch mode. |
GEO DataSet Record
Consult the table below for information about how to use and interpret GEO DataSet Records.
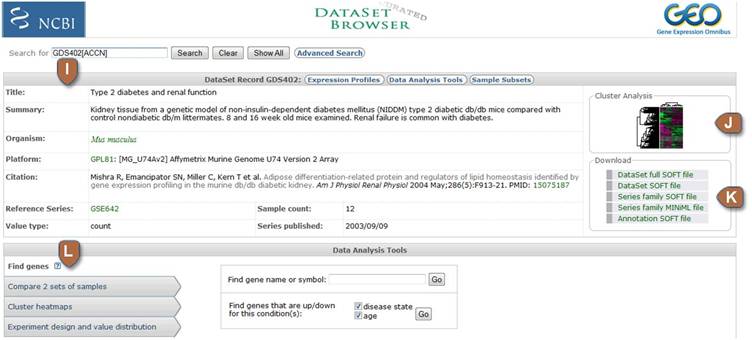
| I | Descriptive information about the DataSet | This section includes the DataSet title, summary, organism, Platform, citation(s), the original (reference) Series upon which the DataSet is based, the type of values the Samples have, the number of Samples the DataSet contains and the date on which the original Series was made public. |
|---|---|---|
| J | Thumbnail cluster image | Click the image to be directed to the full-size default cluster heatmap (Uncentered Correlation UPGMA). See the Cluster heatmaps section below for details on cluster types and cluster program features. |
| K | Download |
Several download options are provided, including: DataSet full SOFT file (recommended): Contains DataSet information, experiment variable subsets, expression value measurements and comprehensive up-to-date gene annotation for the DataSet Platform (plain text, tab-delimited format). DataSet SOFT file: Contains DataSet information, experiment variable subsets, expression value measurements and gene symbols, (plain text, tab-delimited format). Series family SOFT file: Contains the complete, original, submitter-supplied records that form the basis of this DataSet (plain text, tab-delimited format). Series family MINiML file: Contains the complete, original, submitter-supplied records that form the basis of this DataSet (XML format). Annotation SOFT file: Contains comprehensive up-to-date gene annotation for the DataSet Platform (plain text, tab-delimited format). |
| L | Data analysis tools | Information about each of the Data Analysis Tools is provided in the sections below. |
Find genes

| M | Find genes |
Find gene name or symbol: Type in the name or symbol of the gene you want to locate in this DataSet, and you will be directed to relevant Profiles. Find genes that are up/down for this condition(s): Use this feature to help identify genes that are flagged as having subset effects, in other words, genes that are differentially expressed according to experimental subsets. Subsets are groups of Samples within a DataSet that are categorized according to major experimental variables, for example, gender, disease state, etc. For DataSets that have more than one subset type you can restrict retrievals to genes that are expressed differentially in one specific subset type by selecting/deselecting the check boxes as required. The subset effect flag is calculated using the original submitter-supplied expression measurements as contained in the VALUE column of the Sample records. Given the diversity of data and VALUE types and ranges received at GEO, this flag is calculated in a somewhat ad hoc manner and is only an attempt to give potentially differentially-expressed genes higher visibility. To perform more robust analyses, either try a t-test using the Compare 2 sets of samples query tool or upload the DataSet full SOFT file into your favorite microarray analysis software. |
|---|
Compare 2 sets of samples
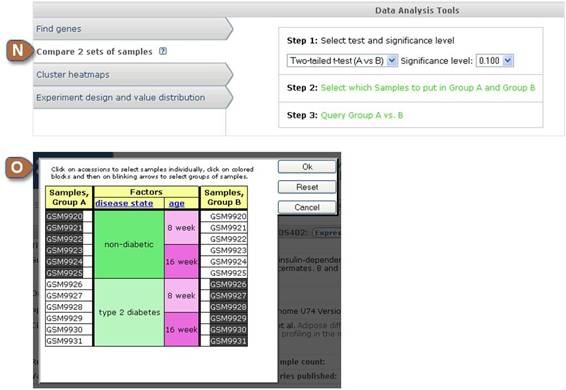
| N | Compare 2 sets of samples |
The purpose of this tool is to help identify genes that display marked differences in expression level between two sets of Samples (Group A and Group B). Typically, users compare Samples that belong to different experiment variable subsets. Step 1: Select the test to perform, and a significance level. Student's t-test, or value or rank means fold differences are available. Step 2: Select which Samples to put in Group A and which Samples to put in Group B. See Section O for details on how to assign Samples to Group A and Group B. Step 3: Query Group A vs. Group B. The t-test score or means fold difference for each group is calculated. Genes that pass the user-selected criteria are presented in GEO Profiles. Notes and caveats: Calculations are based on the original submitter-supplied expression measurements as contained in the VALUE column of the Sample records. Note that there is great diversity in the data values and ranges provided by GEO submitters. The student's t-test is a well established statistical method to determine if the means of two sets of data are really different. There are basic assumptions made by the t-test, thus results may be wrong or misleading based on the validity of these assumptions. The t-test requires at least 2 samples in each group. Value or rank means fold differences is perhaps the most rudimentary method to filter data. Retrievals may have no statistical significance, or compared subsets may be too small to provide any statistic value (e.g., singletons). If values are null or absent they are ignored in the calculations. If one group of values is empty, its value is assumed to be zero for mean group fold. If both groups of values are empty, the profile is skipped. The result set may be empty if no profiles pass the criteria. There is no way to know a priori what filter to use to provide meaningful results or that meaningful results will be obtained. |
|---|---|---|
| O | Assign Samples to Group A and Group B | Select which Samples you want to assign to Group A (left column) and which to Group B (right column). The colored blocks in the middle provide information on the experimental variable subsets within the DataSet. Click on the Sample accession numbers (GSMxxx) to select Samples individually, or click on colored blocks and then on blinking arrows to select entire groups of Samples. You may limit Samples in groups by unchecking the boxes for any groups or Samples you do not wish to include. In the example above, the user has opted to compare all 'non-diabetic' Samples (Group A) with all 'type 2 diabetes' Samples (Group B). |
Cluster heatmaps
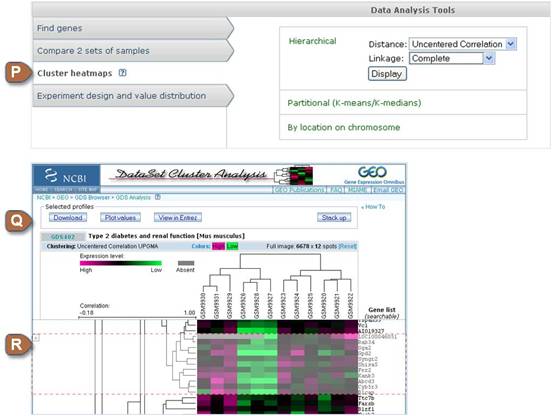
| P | Cluster heatmaps | The full range of cluster types is available from this section, including unsupervised hierarchical clusters, K-means/K-median clusters, and heatmaps organized by location of genes on the chromosome. Background information and details about each cluster type are provided on the GEO Dataset Cluster Analysis page. |
|---|---|---|
| Q | Cluster options | Options for downloading, plotting or exporting selected data to GEO Profiles, and changing the colors of the heatmap are available. For hierarchical clusters, it is also possible to change the cluster type from this area. |
| R | Select regions of interest on the heatmap image | Click the heatmap image to select a region of the cluster for further analysis. A faded selection box will appear; drag and/or resize the height of the box to cover the region of interest. To select more than one region, click the '+' icon on the left side of the selection box then repeat the process to select more regions. To zoom in to a selected region, either double click the selection box or click "Stack up" to view multiple selected regions. Gene symbols are listed on the right side of the zoomed-in cluster. It is possible to search for specific genes within this list using the Ctrl F function of your browser. Use the 'Download', 'Plot values' or 'View in Entrez' buttons to retrieve data for the selected region. |
Experiment design and value distribution

| S | Experiment design and value distribution | Depicts a box plot displaying the distribution of expression values of each Sample within a DataSet. The plot is useful for determining whether the DataSet is normalized, i.e., the value distributions are median-centered across Samples. The colored bars at the bottom of the chart represent experimental variable subsets within the DataSet. Each subset has a type, e.g., 'age', and a description, e.g., '8 week'. For example, in the chart above, the first Sample GSM9920 is derived from an 8 week old, non-diabetic mouse. |
|---|