

NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
Committee on Psychological Testing, Including Validity Testing, for Social Security Administration Disability Determinations; Board on the Health of Select Populations; Institute of Medicine. Psychological Testing in the Service of Disability Determination. Washington (DC): National Academies Press (US); 2015 Jun 29.

Psychological Testing in the Service of Disability Determination.
Show detailsPsychological assessment contributes important information to the understanding of individual characteristics and capabilities, through the collection, integration, and interpretation of information about an individual (Groth-Marnat, 2009; Weiner, 2003). Such information is obtained through a variety of methods and measures, with relevant sources determined by the specific purposes of the evaluation. Sources of information may include
- Records (e.g., medical, educational, occupational, legal) obtained from the referral source;
- Records obtained from other organizations and agencies that have been identified as potentially relevant;
- Interviews conducted with the person being examined;
- Behavioral observations;
- Interviews with corroborative sources such as family members, friends, teachers, and others; and
- Formal psychological or neuropsychological testing.
Agreements across multiple measures and sources, as well as discrepant information, enable the creation of a more comprehensive understanding of the individual being assessed, ultimately leading to more accurate and appropriate clinical conclusions (e.g., diagnosis, recommendations for treatment planning).
The clinical interview remains the foundation of many psychological and neuropsychological assessments. Interviewing may be structured, semistructured, or open in nature, but the goal of the interview remains consistent—to identify the nature of the client's presenting issues, to obtain direct historical information from the examinee regarding such concerns, and to explore historical variables that may be related to the complaints being presented. In addition, the interview element of the assessment process allows for behavioral observations that may be useful in describing the client, as well as discerning the convergence with known diagnoses. Based on the information and observations gained in the interview, assessment instruments may be selected, corroborative informants identified, and other historical records recognized that may aid the clinician in reaching a diagnosis. Conceptually, clinical interviewing explores the presenting complaint(s) (i.e., referral question), informs the understanding of the case history, aids in the development of hypotheses to be examined in the assessment process, and assists in determination of methods to address the hypotheses through formal testing.
An important piece of the assessment process and the focus of this report, psychological testing consists of the administration of one or more standardized procedures under particular environmental conditions (e.g., quiet, good lighting) in order to obtain a representative sample of behavior. Such formal psychological testing may involve the administration of standardized interviews, questionnaires, surveys, and/or tests, selected with regard to the specific examinee and his or her circumstances, that offer information to respond to an assessment question. Assessments, then, serve to respond to questions through the use of tests and other procedures. It is important to note that the selection of appropriate tests requires an understanding of the specific circumstances of the individual being assessed, falling under the purview of clinical judgment. For this reason, the committee refrains from recommending the use of any specific test in this report. Any reference to a specific test is to provide an illustrative example, and should not be interpreted as an endorsement by the committee for use in any specific situation; such a determination is best left to a qualified assessor familiar with the specific circumstances surrounding the assessment.
To respond to questions regarding the use of psychological tests for the assessment of the presence and severity of disability due to mental disorders, this chapter provides an introductory review of psychological testing. The chapter is divided into three sections: (1) types of psychological tests, (2) psychometric properties of tests, and (3) test user qualifications and administration of tests. Where possible an effort has been made to address the context of disability determination; however, the chapter is primarily an introduction to psychological testing.
TYPES OF PSYCHOLOGICAL TESTS
There are many facets to the categorization of psychological tests, and even more if one includes educationally oriented tests; indeed, it is often difficult to differentiate many kinds of tests as purely psychological tests as opposed to educational tests. The ensuing discussion lays out some of the distinctions among such tests; however, it is important to note that there is no one correct cataloging of the types of tests because the different categorizations often overlap. Psychological tests can be categorized by the very nature of the behavior they assess (what they measure), their administration, their scoring, and how they are used. Figure 3-1 illustrates the types of psychological measures as described in this report.
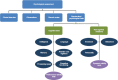
FIGURE 3-1
Components of psychological assessment. NOTE: Performance validity tests do not measure cognition, but are used in conjunction with performance-based cognitive tests to examine whether the examinee is exerting sufficient effort to perform well and responding (more...)
The Nature of Psychological Measures
One of the most common distinctions made among tests relates to whether they are measures of typical behavior (often non-cognitive measures) versus tests of maximal performance (often cognitive tests) (Cronbach, 1949, 1960). A measure of typical behavior asks those completing the instrument to describe what they would commonly do in a given situation. Measures of typical behavior, such as personality, interests, values, and attitudes, may be referred to as non-cognitive measures. A test of maximal performance, obviously enough, asks people to answer questions and solve problems as well as they possibly can. Because tests of maximal performance typically involve cognitive performance, they are often referred to as cognitive tests. Most intelligence and other ability tests would be considered cognitive tests; they can also be known as ability tests, but this would be a more limited category. Non-cognitive measures rarely have correct answers per se, although in some cases (e.g., employment tests) there may be preferred responses; cognitive tests almost always have items that have correct answers. It is through these two lenses—non-cognitive measures and cognitive tests—that the committee examines psychological testing for the purpose of disability evaluation in this report.
One distinction among non-cognitive measures is whether the stimuli composing the measure are structured or unstructured. A structured personality measure, for example, may ask people true-or-false questions about whether they engage in various activities or not. Those are highly structured questions. On the other hand, in administering some commonly used personality measures, the examiner provides an unstructured projective stimulus such as an inkblot or a picture. The test-taker is requested to describe what they see or imagine the inkblot or picture to be describing. The premise of these projective measures is that when presented with ambiguous stimuli an individual will project his or her underlying and unconscious motivations and attitudes. The scoring of these latter measures is often more complex than it is for structured measures.
There is great variety in cognitive tests and what they measure, thus requiring a lengthier explanation. Cognitive tests are often separated into tests of ability and tests of achievement; however, this distinction is not as clear-cut as some would portray it. Both types of tests involve learning. Both kinds of tests involve what the test-taker has learned and can do. However, achievement tests typically involve learning from very specialized education and training experiences; whereas, most ability tests assess learning that has occurred in one's environment. Some aspects of learning are clearly both; for example, vocabulary is learned at home, in one's social environment, and in school. Notably, the best predictor of intelligence test performance is one's vocabulary, which is why it is often given as the first test during intelligence testing or in some cases represents the body of the intelligence test (e.g., the Peabody Picture Vocabulary Test). Conversely, one can also have a vocabulary test based on words one learns only in an academic setting. Intelligence tests are so prevalent in many clinical psychology and neuropsychology situations that we also consider them as neuropsychological measures. Some abilities are measured using subtests from intelligence tests; for example, certain working memory tests would be a common example of an intelligence subtest that is used singly as well. There are also standalone tests of many kinds of specialized abilities.
Some ability tests are broken into verbal and performance tests. Verbal tests, obviously enough, use language to ask questions and demonstrate answers. Performance tests on the other hand minimize the use of language; they can involve solving problems that do not involve language. They may involve manipulating objects, tracing mazes, placing pictures in the proper order, and finishing patterns, for example. This distinction is most commonly used in the case of intelligence tests, but can be used in other ability tests as well. Performance tests are also sometimes used when the test-taker lacks competence in the language of the testing. Many of these tests assess visual spatial tasks. Historically, nonverbal measures were given as intelligence tests for non-English speaking soldiers in the United States as early as World War I. These tests continue to be used in educational and clinical settings given their reduced language component.
Different cognitive tests are also considered to be speeded tests versus power tests. A truly speeded test is one that everyone could get every question correct if they had enough time. Some tests of clerical skills are exactly like this; they may have two lists of paired numbers, for example, where some pairings contain two identical numbers and other pairings are different. The test-taker simply circles the pairings that are identical. Pure power tests are measures in which the only factor influencing performance is how much the test-taker knows or can do. A true power test is one where all test-takers have enough time to do their best; the only question is what they can do. Obviously, few tests are either purely speeded or purely power tests. Most have some combination of both. For example, a testing company may use a rule of thumb that 90 percent of test-takers should complete 90 percent of the questions; however, it should also be clear that the purpose of the testing affects rules of thumb such as this. Few teachers would wish to have many students unable to complete the tests that they take in classes, for example. When test-takers have disabilities that affect their ability to respond to questions quickly, some measures provide extra time, depending upon their purpose and the nature of the characteristics being assessed.
Questions on both achievement and ability tests can involve either recognition or free-response in answering. In educational and intelligence tests, recognition tests typically include multiple-choice questions where one can look for the correct answer among the options, recognize it as correct, and select it as the correct answer. A free-response is analogous to a “fill-in-the-blanks” or an essay question. One must recall or solve the question without choosing from among alternative responses. This distinction also holds for some non-cognitive tests, but the latter distinction is discussed later in this section because it focuses not on recognition but selections. For example, a recognition question on a non-cognitive test might ask someone whether they would rather go ice skating or to a movie; a free recall question would ask the respondent what they like to do for enjoyment.
Cognitive tests of various types can be considered as process or product tests. Take, for example, mathematics tests in school. In some instances, only getting the correct answer leads to a correct response. In other cases, teachers may give partial credit when a student performs the proper operations but does not get the correct answer. Similarly, psychologists and clinical neuropsychologists often observe not only whether a person solves problems correctly (i.e., product), but how the client goes about attempting to solve the problem (i.e., process).
Test Administration
One of the most important distinctions relates to whether tests are group administered or are individually administered by a psychologist, physician, or technician. Tests that traditionally were group administered were paper-and-pencil measures. Often for these measures, the test-taker received both a test booklet and an answer sheet and was required, unless he or she had certain disabilities, to mark his or her responses on the answer sheet. In recent decades, some tests are administered using technology (i.e., computers and other electronic media). There may be some adaptive qualities to tests administered by computer, although not all computer-administered tests are adaptive (technology-administered tests are further discussed below). An individually administered measure is typically provided to the test-taker by a psychologist, physician, or technician. More faith is often provided to the individually administered measure, because the trained professional administering the test can make judgments during the testing that affect the administration, scoring, and other observations related to the test.
Tests can be administered in an adaptive or linear fashion, whether by computer or individual administrator. A linear test is one in which questions are administered one after another in a pre-arranged order. An adaptive test is one in which the test-taker's performance on earlier items affects the questions he or she received subsequently. Typically, if the test-taker is answering the first questions correctly or in accordance with preset or expected response algorithms, for example, the next questions are still more difficult until the level appropriate for the examinee performance is best reached or the test is completed. If one does not answer the first questions correctly or as typically expected in the case of a non-cognitive measure, then easier questions would generally be presented to the test-taker.
Tests can be administered in written (keyboard or paper-and-pencil) fashion, orally, using an assistive device (most typically for individuals with motor disabilities), or in performance format, as previously noted. It is generally difficult to administer oral or performance tests in a group situation; however, some electronic media are making it possible to administer such tests without human examiners.
Another distinction among measures relates to who the respondent is. In most cases, the test-taker him- or herself is the respondent to any questions posed by the psychologist or physician. In the case of a young child, many individuals with autism, or an individual, for example, who has lost language ability, the examiner may need to ask others who know the individual (parents, teachers, spouses, family members) how they behave and to describe their personality, typical behaviors, and so on.
Scoring Differences
Tests are categorized as objectively scored, subjectively scored, or in some instances, both. An objectively scored instrument is one where the correct answers are counted and they either are, or they are converted to, the final scoring. Such tests may be scored manually or using optical scanning machines, computerized software, software used by other electronic media, or even templates (keys) that are placed over answer sheets where a person counts the number of correct answers. Examiner ratings and self-report interpretations are determined by the professional using a rubric or scoring system to convert the examinee's responses to a score, whether numerical or not. Sometimes subjective scores may include both quantitative and qualitative summaries or narrative descriptions of the performance of an individual.
Scores on tests are often considered to be norm-referenced (or normative) or criterion-referenced. Norm-referenced cognitive measures (such as college and graduate school admissions measures) inform the test-takers where they stand relative to others in the distribution. For example, an applicant to a college may learn that she is at the 60th percentile, meaning that she has scored better than 60 percent of those taking the test and less well than 40 percent of the same norm group. Likewise, most if not all intelligence tests are norm-referenced, and most other ability tests are as well. In recent years there has been more of a call for criterion-referenced tests, especially in education (Hambleton and Pitoniak, 2006). For criterion-referenced tests, one's score is not compared to the other members of the test-taking population but rather to a fixed standard. High school graduation tests, licensure tests, and other tests that decide whether test-takers have met minimal competency requirements are examples of criterion-referenced measures. When one takes a driving test to earn one's driver's license, for example, one does not find out where one's driving falls in the distribution of national or statewide drivers, one only passes or fails.
Test Content
As noted previously, the most important distinction among most psychological tests is whether they are assessing cognitive versus non-cognitive qualities. In clinical psychological and neuropsychological settings such as are the concern of this volume, the most common cognitive tests are intelligence tests, other clinical neuropsychological measures, and performance validity measures. Many tests used by clinical neuropsychologists, psychiatrists, technicians, or others assess specific types of functioning, such as memory or problem solving. Performance validity measures are typically short assessments and are sometimes interspersed among components of other assessments that help the psychologist determine whether the examinee is exerting sufficient effort to perform well and responding to the best of his or her ability. Most common non-cognitive measures in clinical psychology and neuropsychology settings are personality measures and symptom validity measures. Some personality tests, such as the Minnesota Multiphasic Personality Inventory (MMPI), assess the degree to which someone expresses behaviors that are seen as atypical in relation to the norming sample.1 Other personality tests are more normative and try to provide information about the client to the therapist. Symptom validity measures are scales, like performance validity measures, that may be interspersed throughout a longer assessment to examine whether a person is portraying him- or herself in an honest and truthful manner. Somewhere between these two types of tests—cognitive and non-cognitive—are various measures of adaptive functioning that often include both cognitive and non-cognitive components.
PSYCHOMETRICS: EXAMINING THE PROPERTIES OF TEST SCORES
Psychometrics is the scientific study—including the development, interpretation, and evaluation—of psychological tests and measures used to assess variability in behavior and link such variability to psychological phenomena. In evaluating the quality of psychological measures we are traditionally concerned primarily with test reliability (i.e., consistency), validity (i.e., accuracy of interpretations and use), and fairness (i.e., equivalence of usage across groups). This section provides a general overview of these concepts to help orient the reader for the ensuing discussions in Chapters 4 and 5. In addition, given the implications of applying psychological measures with subjects from diverse racial and ethnic backgrounds, issues of equivalence and fairness in psychological testing are also presented.
Reliability
Reliability refers to the degree to which scores from a test are stable and results are consistent. When constructs are not reliably measured the obtained scores will not approximate a true value in relation to the psychological variable being measured. It is important to understand that observed or obtained test scores are considered to be composed of true and error elements. A standard error of measurement is often presented to describe, within a level of confidence (e.g., 95 percent), that a given range of test scores contains a person's true score, which acknowledges the presence of some degree of error in test scores and that obtained test scores are only estimates of true scores (Geisinger, 2013).
Reliability is generally assessed in four ways:
- 1.
Test-retest: Consistency of test scores over time (stability, temporal consistency);
- 2.
Inter-rater: Consistency of test scores among independent judges;
- 3.
Parallel or alternate forms: Consistency of scores across different forms of the test (stability and equivalence); and
- 4.
Internal consistency: Consistency of different items intended to measure the same thing within the test (homogeneity). A special case of internal consistency reliability is split-half where scores on two halves of a single test are compared and this comparison may be converted into an index of reliability.
A number of factors can affect the reliability of a test's scores. These include time between two testing administrations that affect test-retest and alternate-forms reliability, and similarity of content and expectations of subjects regarding different elements of the test in alternate forms, split-half, and internal consistency approaches. In addition, changes in subjects over time and introduced by physical ailments, emotional problems, or the subject's environment, or test-based factors such as poor test instructions, subjective scoring, and guessing will also affect test reliability. It is important to note that a test can generate reliable scores in one context and not in another, and that inferences that can be made from different estimates of reliability are not interchangeable (Geisinger, 2013).
Validity
While the scores resulting from a test may be deemed reliable, this finding does not necessarily mean that scores from the test have validity. Validity is defined as “the degree to which evidence and theory support the interpretations of test scores for proposed uses of tests” (AERA et al., 2014, p. 11). In discussing validity, it is important to highlight that validity refers not to the measure itself (i.e., a psychological test is not valid or invalid) or the scores derived from the measure, but rather the interpretation and use of the measure's scores. To be considered valid, the interpretation of test scores must be grounded in psychological theory and empirical evidence that demonstrates a relationship between the test and what it purports to measure (Furr and Bacharach, 2013; Sireci and Sukin, 2013). Historically, the fields of psychology and education have described three primary types of evidence related to validity (Sattler, 2014; Sireci and Sukin, 2013):
- 1.
Construct evidence of validity: The degree to which an individual's test scores correlate with the theoretical concept the test is designed to measure (i.e., evidence that scores on a test correlate relatively highly with scores on theoretically similar measures and relatively poorly with scores on theoretically dissimilar measures);
- 2.
Content evidence of validity: The degree to which the test content represents the targeted subject matter and supports a test's use for its intended purposes; and
- 3.
Criterion-related evidence of validity: The degree to which the test's score correlates with other measurable, reliable, and relevant variables (i.e., criterion) thought to measure the same construct.
Other kinds of validity with relevance to SSA have been advanced in the literature, but are not completely accepted in professional standards as types of validity per se. These include
- 1.
Diagnostic validity: The degree to which psychological tests are truly aiding in the formulation of an appropriate diagnosis.
- 2.
Ecological validity: The degree to which test scores represent everyday levels of functioning (e.g., impact of disability on an individual's ability to function independently).
- 3.
Cultural validity: The degree to which test content and procedures accurately reflect the sociocultural context of the subjects being tested.
Each of these forms of validity poses complex questions regarding the use of particular psychological measures with the SSA population. For example, ecological validity is especially critical in the use of psychological tests with SSA given that the focus of the assessment is on examining everyday levels of functioning. Measures like intelligence tests have been sometimes criticized for lacking ecological validity (Groth-Marnat, 2009; Groth-Marnat and Teal, 2000). Alternatively, “research suggests that many neuropsychological tests have a moderate level of ecological validity when predicting everyday cognitive functioning” (Chaytor and Schmitter-Edgecombe, 2003, p. 181).
More recent discussions on validity have shifted toward an argument-based approach to validity, using a variety of evidence to build a case for validity of test score interpretation (Furr and Bacharach, 2013). In this approach, construct validity is viewed as an overarching paradigm under which evidence is gathered from multiple sources to build a case for validity of test score interpretation. Five key sources of validity evidence that affect the degree to which a test fulfills its purpose are generally considered (AERA et al., 2014; Furr and Bacharach, 2013; Sireci and Sukin, 2013):
- 1.
Test content: Does the test content reflect the important facets of the construct being measured? Are the test items relevant and appropriate for measuring the construct and congruent with the purpose of testing?
- 2.
Relation to other variables: Is there a relationship between test scores and other criterion or constructs that are expected to be related?
- 3.
Internal structure: Does the actual structure of the test match the theoretically based structure of the construct?
- 4.
Response processes: Are respondents applying the theoretical constructs or processes the test is designed to measure?
- 5.
Consequences of testing: What are the intended and unintended consequences of testing?
Standardization and Testing Norms
As part of the development of any psychometrically sound measure, explicit methods and procedures by which tasks should be administered are determined and clearly spelled out. This is what is commonly known as standardization. Typical standardized administration procedures or expectations include (1) a quiet, relatively distraction-free environment, (2) precise reading of scripted instructions, and (3) provision of necessary tools or stimuli. All examiners use such methods and procedures during the process of collecting the normative data, and such procedures normally should be used in any other administration, which enables application of normative data to the individual being evaluated (Lezak et al., 2012).
Standardized tests provide a set of normative data (i.e., norms), or scores derived from groups of people for whom the measure is designed (i.e., the designated population) to which an individual's performance can be compared. Norms consist of transformed scores such as percentiles, cumulative percentiles, and standard scores (e.g., T-scores, Z-scores, stanines, IQs), allowing for comparison of an individual's test results with the designated population. Without standardized administration, the individual's performance may not accurately reflect his or her ability. For example, an individual's abilities may be overestimated if the examiner provides additional information or guidance than what is outlined in the test administration manual. Conversely, a claimant's abilities may be underestimated if appropriate instructions, examples, or prompts are not presented. When nonstandardized administration techniques must be used, norms should be used with caution due to the systematic error that may be introduced into the testing process; this topic is discussed in detail later in the chapter.
It is important to clearly understand the population for which a particular test is intended. The standardization sample is another name for the norm group. Norms enable one to make meaningful interpretations of obtained test scores, such as making predictions based on evidence. Developing appropriate norms depends on size and representativeness of the sample. In general, the more people in the norm group the closer the approximation to a population distribution so long as they represent the group who will be taking the test.
Norms should be based upon representative samples of individuals from the intended test population, as each person should have an equal chance of being in the standardization sample. Stratified samples enable the test developer to identify particular demographic characteristics represented in the population and more closely approximate these features in proportion to the population. For example, intelligence test scores are often established based upon census-based norming with proportional representation of demographic features including race and ethnic group membership, parental education, socioeconomic status, and geographic region of the country.
When tests are applied to individuals for whom the test was not intended and, hence, were not included as part of the norm group, inaccurate scores and subsequent misinterpretations may result. Tests administered to persons with disabilities often raise complex issues. Test users sometimes use psychological tests that were not developed or normed for individuals with disabilities. It is critical that tests used with such persons (including SSA disability claimants) include attention to representative norming samples; when such norming samples are not available, it is important for the assessor to note that the test or tests used are not based on representative norming samples and the potential implications for interpretation (Turner et al., 2001).
Test Fairness in High-Stakes Testing Decisions
Performance on psychological tests often has significant implications (high stakes) in our society. Tests are in part the gatekeepers for educational and occupational opportunities and play a role in SSA determinations. As such, results of psychological testing may have positive or negative consequences for an individual. Often such consequences are intended; however, there is the possibility for unintended negative consequences. It is imperative that issues of test fairness be addressed so no individual or group is disadvantaged in the testing process based upon factors unrelated to the areas measured by the test. Biases simply cannot be present in these kinds of professional determinations. Moreover, it is imperative that research demonstrates that measures can be fairly and equivalently used with members of the various subgroups in our population. It is important to note that there are people from many language and cultural groups for whom there are no available tests with norms that are appropriately representative for them. As noted above, in such cases it is important for assessors to include a statement about this situation whenever it applies and potential implications on scores and resultant interpretation.
While all tests reflect what is valued within a particular cultural context (i.e., cultural loading), bias refers to the presence of systematic error in the measurement of a psychological construct. Bias leads to inaccurate test results given that scores reflect either overestimations or underestimations of what is being measured. When bias occurs based upon culturally related variables (e.g., race, ethnicity, social class, gender, educational level) then there is evidence of cultural test bias (Suzuki et al., 2014).
Relevant considerations pertain to issues of equivalence in psychological testing as characterized by the following (Suzuki et al., 2014, p. 260):
- 1.
Functional: Whether the construct being measured occurs with equal frequency across groups;
- 2.
Conceptual: Whether the item information is familiar across groups and means the same thing in various cultures;
- 3.
Scalar: Whether average score differences reflect the same degree, intensity, or magnitude for different cultural groups;
- 4.
Linguistic: Whether the language used has similar meaning across groups; and
- 5.
Metric: Whether the scale measures the same behavioral qualities or characteristics and the measure has similar psychometric properties in different cultures.
It must be established that the measure is operating appropriately in various cultural contexts. Test developers address issues of equivalence through procedures including
- Expert panel reviews (i.e., professionals review item content and provide informed judgments regarding potential biases);
- Examination of differential item functioning (DIF) among groups;
- Statistical procedures allowing comparison of psychometric features of the test (e.g., reliability coefficients) based on different population samples;
- Exploratory and confirmatory factor analysis, structural equation modeling (i.e., examination of the similarities and differences of the constructs structure), and measurement invariance; and
- Mean score differences taking into consideration the spread of scores within particular racial and ethnic groups as well as among groups.
Cultural equivalence refers to whether “interpretations of psychological measurements, assessments, and observations are similar if not equal across different ethnocultural populations” (Trimble, 2010, p. 316). Cultural equivalence is a higher order form of equivalence that is dependent on measures meeting specific criteria indicating that a measure may be appropriately used with other cultural groups beyond the one for which it was originally developed. Trimble (2010) notes that there may be upward of 50 or more types of equivalence that affect interpretive and procedural practices in order to establish cultural equivalence.
Item Response Theory and Tests2
For most of the 20th century, the dominant measurement model was called classical test theory. This model was based on the notion that all scores were composed of two components: true score and error. One can imagine a “true score” as a hypothetical value that would represent a person's actual score were there no error present in the assessment (and unfortunately, there is always some error, both random and systematic). The model further assumes that all error is random and that any correlation between error and some other variable, such as true scores, is effectively zero (Geisinger, 2013). The approach leans heavily on reliability theory, which is largely derived from the premises mentioned above.
Since the 1950s and largely since the 1970s, a newer mathematically sophisticated model developed called item response theory (IRT). The premise of these IRT models is most easily understood in the context of cognitive tests, where there is a correct answer to questions. The simplest IRT model is based on the notion that the answering of a question is generally based on only two factors: the difficulty of the question and the ability level of the test-taker. Computer-adaptive testing estimates scores of the test-taker after each response to a question and adjusts the administration of the next question accordingly. For example, if a test-taker answers a question correctly, he or she is likely to receive a more difficult question next. If one, on the other hand, answers incorrectly, he or she is more likely to receive an easier question, with the “running score” held by the computer adjusted accordingly. It has been found that such computer-adaptive tests can be very efficient.
IRT models have made the equating of test forms far easier. Equating tests permits one to use different forms of the same examination with different test items to yield fully comparable scores due to slightly different item difficulties across forms. To convert the values of item difficulty to determine the test-taker's ability scores one needs to have some common items across various tests; these common items are known as anchor items. Using such items, one can essentially establish a fixed reference group and base judgments from other groups on these values.
As noted above, there are a number of common IRT models. Among the most common are the one-, two-, and three-parameter models. The one-parameter model is the one already described; the only item parameter is item difficulty. A two-parameter model adds a second parameter to the first, related to item discrimination. Item discrimination is the ability of the item to differentiate those lacking the ability in high degree from those holding it. Such two-parameter models are often used for tests like essay tests where one cannot achieve a high score by guessing or using other means to answer currently. The three-parameter IRT model contains a third parameter, that factor related to chance level correct scoring. This parameter is sometimes called the pseudo-guessing parameter, and this model is generally used for large-scale multiple-choice testing programs.
These models, because of their lessened reliance on the sampling of test-takers, are very useful in the equating of tests that is the setting of scores to be equivalent regardless of the form of the test one takes. In some high-stakes admissions tests such as the GRE, MCAT, and GMAT, for example, forms are scored and equated by virtue of IRT methods, which can perform such operations more efficiently and accurately than can be done with classical statistics.
TEST USER QUALIFICATIONS
The test user is generally considered the person responsible for appropriate use of psychological tests, including selection, administration, interpretation, and use of results (AERA et al., 2014). Test user qualifications include attention to the purchase of psychological measures that specify levels of training, educational degree, areas of knowledge within domain of assessment (e.g., ethical administration, scoring, and interpretation of clinical assessment), certifications, licensure, and membership in professional organizations. Test user qualifications require psychometric knowledge and skills as well as training regarding the responsible use of tests (e.g., ethics), in particular, psychometric and measurement knowledge (i.e., descriptive statistics, reliability and measurement error, validity and the meaning of test scores, normative interpretation of test scores, selection of appropriate tests, and test administration procedures). In addition, test user guidelines highlight the importance of understanding the impact of ethnic, racial, cultural, gender, age, educational, and linguistic characteristics in the selection and use of psychological tests (Turner et al., 2001).
Test publishers provide detailed manuals regarding the operational definition of the construct being assessed, norming sample, reading level of test items, completion time, administration, and scoring and interpretation of test scores. Directions presented to the examinee are provided verbatim and sample responses are often provided to assist the examiner in determining a right or wrong response or in awarding numbers of points to a particular answer. Ethical and legal knowledge regarding assessment competencies, confidentiality of test information, test security, and legal rights of test-takers are imperative. Resources like the Mental Measurements yearbook (MMy) provide descriptive information and evaluative reviews of commercially available tests to promote and encourage informed test selection (Buros, 2015). To be included, tests must contain sufficient documentation regarding their psychometric quality (e.g., validity, reliability, norming).
Test Administration and Interpretation
In accordance with the Standards for Educational and Psychological Testing (AERA et al., 2014) and the APA's Guidelines for Test User Qualifications (Turner et al., 2001), many publishers of psychological tests employ a tiered system of qualification levels (generally A, B, C) required for the purchase, administration, and interpretation of such tests (e.g., PAR, n.d.; Pearson Education, 2015). Many instruments, such as those discussed throughout this report, would be considered qualification level C assessment methods, generally requiring an advanced degree, specialized psychometric and measurement knowledge, and formal training in administration, scoring, and interpretation. However, some may have less stringent requirements, for example, a bachelor's or master's degree in a related field and specialized training in psychometric assessment (often classified level B), or no special requirements (often classified level A) for purchase and use. While such categories serve as a general guide for necessary qualifications, individual test manuals provide additional detail and specific qualifications necessary for administration, scoring, and interpretation of the test or measure.
Given the need for the use of standardized procedures, any person administering cognitive or neuropsychological measures must be well trained in standardized administration protocols. He or she should possess the interpersonal skills necessary to build rapport with the individual being tested in order to foster cooperation and maximal effort during testing. Additionally, individuals administering tests should understand important psychometric properties, including validity and reliability, as well as factors that could emerge during testing to place either at risk. Many doctoral-level psychologists are well trained in test administration; in general, psychologists from clinical, counseling, school, or educational graduate psychology programs receive training in psychological test administration. For cases in which cognitive deficits are being evaluated, a neuropsychologist may be needed to most accurately evaluate cognitive functioning (see Chapter 5 for a more detailed discussion on administration and interpretation of cognitive tests). The use of non-doctoral-level psychometrists or technicians in psychological and neuropsychological test administration and scoring is also a widely accepted standard of practice (APA, 2010; Brandt and van Gorp, 1999; Pearson Education, 2015). Psychometrists are often bachelor's- or master's-level individuals who have received additional specialized training in standardized test administration and scoring. They do not practice independently or interpret test scores, but rather work under the close supervision and direction of doctoral-level clinical psychologists or neuropsychologists.
Interpretation of testing results requires a higher degree of clinical training than administration alone. Threats to the validity of any psychological measure of a self-report nature oblige the test interpreter to understand the test and principles of test construction. In fact, interpreting tests results without such knowledge would violate the ethics code established for the profession of psychology (APA, 2010). SSA requires psychological testing be “individually administered by a qualified specialist … currently licensed or certified in the state to administer, score, and interpret psychological tests and have the training and experience to perform the test” (SSA, n.d.). Most doctoral-level clinical psychologists who have been trained in psychometric test administration are also trained in test interpretation. SSA (n.d.) also requires individuals who administer more specific cognitive or neuropsychological evaluations “be properly trained in this area of neuroscience.” As such, clinical neuropsychologists—individuals who have been specifically trained to interpret testing results within the framework of brain-behavior relationships and who have achieved certain educational and training benchmarks as delineated by national professional organizations—may be required to interpret tests of a cognitive nature (AACN, 2007; NAN, 2001).
Use of Interpreters and Other Nonstandardized Test Administration Techniques
Modification of procedures, including the use of interpreters and the administration of nonstandardized assessment procedures, may pose unique challenges to the psychologist by potentially introducing systematic error into the testing process. Such errors may be related to language, the use of translators, or examinee abilities (e.g., sensory, perceptual, and/or motor capacity). For example, if one uses a language interpreter, the potential for mistranslation may yield inaccurate scores. Use of translators is a nonpreferred option, and assessors need to be familiar with both the language and culture from which an individual comes to properly interpret test results, or even infer whether specific measures are appropriate. The adaptation of tests has become big business for testing companies, and many tests, most often measures developed in English for use in the United States, are being adapted for use in other countries. Such measures require changes in language, but translators must also be knowledgeable about culture and the environment of the region from which a person comes (ITC, 2005).
For sensory, perceptual, or motor abilities, one may be altering the construct that the test is designed to measure. In both of these examples, one could be obtaining scores for which there is no referenced normative group to allow for accurate interpretation of results. While a thorough discussion of these concepts is beyond the scope of this report and is presented elsewhere, it may be stated that when a test is administered following a procedure that is outside of that which has been developed in the standardization process, conclusions drawn must recognize the potential for error in their creation.
PSYCHOLOGICAL TESTING IN THE CONTEXT OF DISABILITY DETERMINATIONS
As noted in Chapter 2, SSA indicates that objective medical evidence may include the results of standardized psychological tests. Given the great variety of psychological tests, some are more objective than others. Whether a psychological test is appropriately considered objective has much to do with the process of scoring. For example, unstructured measures that call for open-ended responding rely on professional judgment and interpretation in scoring; thus, such measures are considered less than objective. In contrast, standardized psychological tests and measures, such as those discussed in the ensuing chapters, are structured and objectively scored. In the case of non-cognitive self-report measures, the respondent generally answers questions regarding typical behavior by choosing from a set of predetermined answers. With cognitive tests, the respondent answers questions or solves problems, which usually have correct answers, as well as he or she possibly can. Such measures generally provide a set of normative data (i.e., norms), or scores derived from groups of people for whom the measure is designed (i.e., the designated population), to which an individual's responses or performance can be compared. Therefore, standardized psychological tests and measures rely less on clinical judgment and are considered to be more objective than those that depend on subjective scoring. Unlike measurements such as weight or blood pressure standardized psychological tests require the individual's cooperation with respect to self-report or performance on a task. The inclusion of validity testing, which will be discussed further in Chapters 4 and 5, in the test or test battery allows for greater confidence in the test results. Standardized psychological tests that are appropriately administered and interpreted can be considered objective evidence.
The use of psychological tests in disability determinations has critical implications for clients. As noted earlier, issues surrounding ecological validity (i.e., whether test performance accurately reflects real-world behavior) is of primary importance in SSA determination. Two approaches have been identified in relation to the ecological validity of neuropsychological assessment. The first focuses on “how well the test captures the essence of everyday cognitive skills” in order to “identify people who have difficulty performing real-world tasks, regardless of the etiology of the problem” (i.e., verisimilitude), and the second “relates performance on traditional neuropsychological tests to measures of real-world functioning, such as employment status, questionnaires, or clinician ratings” (i.e., veridicality) (Chaytor and Schmitter-Edgecombe, 2003, pp. 182–183). Establishing ecological validity is a complicated endeavor given the potential effect of non-cognitive factors (e.g., emotional, physical, and environmental) on test and everyday performance. Specific concerns regarding test performance include (1) the test environment is often not representative (i.e., artificial), (2) testing yields only samples of behavior that may fluctuate depending on context, and (3) clients may possess compensatory strategies that are not employable during the testing situation; therefore, obtained scores underestimate the test-taker's abilities.
Activities of daily living (ADLs) and the client's likelihood of returning to work are important considerations in disability determinations. Occupational status, however, is complex and often multidetermined requiring that psychological test data be complemented with other sources of information in the evaluation process (e.g., observation, informant ratings, environmental assessments) (Chaytor and Schmitter-Edgecombe, 2003). Table 3-1 highlights major mental disorders, relevant types of psychological measures, and domains of functioning.
TABLE 3-1
Listings for Mental Disorders and Types of Psychological Tests.
Determination of disability is dependent on two key factors: the existence of a medically determinable impairment and associated limitations on functioning. As discussed in detail in Chapter 2, applications for disability follow a five-step sequential disability determination process. At Step 3 in the process, the applicant's reported impairments are evaluated to determine whether they meet or equal the medical criteria codified in SSA's Listing of Impairments. This includes specific symptoms, signs, and laboratory findings that substantiate the existence of an impairment (i.e., Paragraph A criteria) and evidence of associated functional limitations (i.e., Paragraph B criteria). If an applicant's impairments meet or equal the listing criteria, the claim is allowed. If not, residual functional capacity, including mental residual functional capacity, is assessed. This includes whether the applicant has the capacity for past work (Step 4) or any work in the national economy (Step 5).
SSA uses a standard assessment that examines functioning in four domains: understanding and memory, sustained concentration and persistence, social interaction, and adaptation. Psychological testing may play a key role in understanding a client's functioning in each of these areas. Box 3-1 describes ways in which these four areas of core mental residual functional capacity are assessed ecologically. Psychological assessments often address these areas in a more structured manner through interviews, standardized measures, checklists, observations, and other assessment procedures.
BOX 3-1
Descriptions of Tests by Four Areas of Core Mental Residual Functional Capacity. Remember location and work-like procedures Understand and remember very short and simple instructions
This chapter has identified some of the basic foundations underlying the use of psychological tests including basic psychometric principles and issues regarding test fairness. Applications of tests can inform disability determinations. The next two chapters build on this overview, examining the types of psychological tests that may be useful in this process, including a review of selected individual tests that have been developed for measuring validity of presentation. Chapter 4 focuses on non-cognitive, self-report measures and symptom validity tests. Chapter 5 then focuses on cognitive tests and associated performance validity tests. Strengths and limitations of various instruments are offered, in order to subsequently explore the relevance for different types of tests for different claims, per category of disorder, with a focus on establishing the validity of the client's claim.
REFERENCES
- AACN (American Academy of Clinical Neuropsychology). AACN practice guidelines for neuropsychological assessment and consultation. Clinical Neuropsychology. 2007;21(2):209–231. [PubMed: 17455014]
- AERA (American Educational Research Association), APA (American Psychological Association), and NCME (National Council on Measurement in Education). Standards for educational and psychological testing. Washington, DC: AERA; 2014.
- APA. Ethical principles of psychologists and code of conduct. 2010. [March 9, 2015]. http://www
.apa.org/ethics/code . - Brandt J, van Gorp W. American Academy of Clinical Neuropsychology policy on the use of non-doctoral-level personnel in conducting clinical neuropsychological evaluations. The Clinical Neuropsychologist. 1999;13(4):385–385.
- Buros Center for Testing. Test reviews and information. 2015. [March 19, 2015]. http://buros
.org/test-reviews-information . - Chaytor N, Schmitter-Edgecombe M. The ecological validity of neuropsychological tests: A review of the literature on everyday cognitive skills. Neuropsychology Review. 2003;13(4):181–197. [PubMed: 15000225]
- Cronbach LJ. Essentials of psychological testing. New York: Harper; 1949.
- Cronbach LJ. Essentials of psychological testing. 2nd. Oxford, England: Harper; 1960.
- De Ayala RJ. Theory and practice of item response theory. New York: Guilford Publications; 2009.
- DeMars C. Item response theory. New York: Oxford University Press; 2010.
- Furr RM, Bacharach VR. Psychometrics: An introduction. Thousand Oaks, CA: Sage Publications, Inc.; 2013.
- Geisinger KF. Reliability. Geisinger KF, Bracken BA, Carlson JF, Hansen JC, Kuncel NR, Reise SP, Rodriguez MC, editors. Washington, DC: APA; APA handbook of testing and assessment in psychology. 2013;1
- Groth-Marnat G. Handbook of psychological assessment. Hoboken, NJ: John Wiley & Sons; 2009.
- Groth-Marnat G, Teal M. Block design as a measure of everyday spatial ability: A study of ecological validity. Perceptual and Motor Skills. 2000;90(2):522–526. [PubMed: 10833749]
- Hambleton RK, Pitoniak MJ. Setting performance standards. Educational Measurement. 2006;4:433–470.
- ITC (International Test Commission). ITC guidelines for translating and adaptating tests. Geneva, Switzerland: ITC; 2005.
- Lezak M, Howieson D, Bigler E, Tranel D. Neuropsychological assessment. 5th. New York: Oxford University Press; 2012.
- NAN (National Academy of Neuropsychology). NAN definition of a clinical neuropsychologist: Official position of the National Academy of Neuropsychology. 2001. [November 25, 2014]. https://www
.nanonline .org/docs/PAIC/PDFs /NANPositionDefNeuro.pdf . - PAR (Psychological Assessment Resources). Qualifications levels. 2015. [January 5, 2015]. http://www4
.parinc.com /Supp/Qualifications.aspx . - Pearson Education. Qualifications policy. 2015. [January 5, 2015]. http://www
.pearsonclinical .com/psychology/qualifications .html . - Sattler JM. Foundations of behavioral, social, and clinical assessment of children. 6th. La Mesa, CA: Jerome M. Sattler, Publisher, Inc.; 2014.
- Sireci SG, Sukin T. Test validity. Geisinger KF, Bracken BA, Carlson JF, Hansen JC, Kuncel NR, Reise SP, Rodriguez MC, editors. Washington, DC: APA; APA handbook of testing and assessment in psychology. 2013;1
- SSA (Social Security Administration). Disability evaluation under social security—Part III: Listing of impairments—Adult listings (Part A)—section 12.00 mental disorders. n.d. [November 14, 2014]. http://www
.ssa.gov/disability /professionals/bluebook/12 .00-MentalDisorders-Adult.htm . - Suzuki LA, Naqvi S, Hill JS. Assessing intelligence in a cultural context. Leong FTL, Comas-Diaz L, Nagayama Hall GC, McLoyd VC, Trimble JE, editors. Washington, DC: APA; APA handbook of multicultural psychology. 2014;1
- Trimble JE. Encyclopedia of cross-cultural school psychology. New York: Springer; 2010. Cultural measurement equivalence; pp. 316–318.
- Turner SM, DeMers ST, Fox HR, Reed G. APA's guidelines for test user qualifications: An executive summary. American Psychologist. 2001;56(12):1099.
- Weiner IB. The assessment process. In: Weiner IB, editor. Handbook of psychology. Hoboken, NJ: John Wiley & Sons; 2003.
Footnotes
- 1
This may be in comparison to a nationally representative norming sample, or with certain tests or measures, such as the MMPI, particular clinically diagnostic samples.
- 2
The brief overview presented here draws on the works of De Ayala (2009) and DeMars (2010), to which the reader is directed for additional information.
- PubMedLinks to PubMed
- Overview of Psychological Testing - Psychological Testing in the Service of Disa...Overview of Psychological Testing - Psychological Testing in the Service of Disability Determination
Your browsing activity is empty.
Activity recording is turned off.
See more...