

NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
Varki A, Cummings RD, Esko JD, et al., editors. Essentials of Glycobiology [Internet]. 3rd edition. Cold Spring Harbor (NY): Cold Spring Harbor Laboratory Press; 2015-2017. doi: 10.1101/glycobiology.3e.008


Essentials of Glycobiology [Internet]. 3rd edition.
Show details
A multitude of glycosyltransferases (GTs), glycoside hydrolases (GHs; also called glycosidases), nucleotide sugar transporters, and other enzymes are required to synthesize and metabolize glycans. Also, many genes encode glycan-binding proteins (GBPs), which recognize specific glycan structures. This chapter provides a genomic perspective of the genes that code for GTs, GHs, and GBPs.
THE GLYCOME
The glycome comprises all the glycan structures synthesized by an organism (Chapter 51). It is analogous to the genome, the transcriptome, and/or the proteome but even more dynamic, and it has higher structural complexity that has yet to be fully defined. Cells of different types will synthesize a subset of the glycome based on their differentiation state and physiological environment. The human and mouse glycomes have many glycan structures in common, but a few are unique or have divergent functional properties. For example, unlike humans, rodents synthesize cytidine monophospho-N-glycolylneuraminic acid (CMP-Neu5Gc), for Neu5Gc transfer to N- and O-glycans (Chapter 15). Similarly, the gene encoding α1-3 galactosyltransferase is functional in the mouse but not in human (Chapter 20). The human and fly genomes include orthologous genes that encode GTs that catalyze the same reaction, but they also have GTs that are unique. Thus, protein O-fucosyltransferase 1 (POFUT1) in mammals and Ofut1 in flies transfer fucose to Notch receptors and are examples of a conserved GT. In contrast, flies do not make complex N-glycans with four branches, which are common in mammalian glycoproteins (Chapters 9 and 20). Additionally, flies make unique glycolipids absent from mammals that are important for conserved signaling pathways mediated by the epidermal growth factor (EGF) receptor or Notch receptors (Chapter 26).
GENOMICS OF GLYCOSYLATION
The genome encodes all of the enzymes, transporters, and other activities necessary to construct the glycome of an organism. Few complete genomes were sequenced in 1999 when this book first appeared. This grew to approximately 650 genomes by the second edition (2009) and has now increased dramatically, with more than 5000 included in the Carbohydrate-Active Enzymes (CAZy) database of the 25,000 genomes at the stage of permanent draft (Genomes Online Database). Similarly, the number of GTs with a known three-dimensional structure has grown from one in 1999 to 158 in 2015. The CAZy database is dedicated to coping with the staggering increases in sequences and structures (National Center for Biotechnology Information).1
In the pregenomic era, the glycobiology of mammals, invertebrates, plants, bacteria, and viruses did not overlap extensively, and progress in one domain did not immediately benefit the others. With several genomes being released each day, the evolutionary history of GT sequences has emerged. We now know that GTs from various organisms display the same basic structural folds, and we can harness the relationships between the sequence and the specificity of a GT (Chapter 6). The content of genomes can also be examined from a glycobiology perspective (e.g., by listing candidate GHs or GTs in a genome) and compared across genomes to see which families have expanded or disappeared during evolution. Examination of completely sequenced genomes suggests that a few percent of any genome encodes GTs and GHs. The number of GT genes in different organisms is variable, but varies much less within a taxonomic clade. The number of GTs tends to be greater than the number of GHs, except for organisms that forage on complex glycans as a carbon source. Thus, the genomes of saprophytic fungi and bacteria of the intestinal flora can encode several hundred enzymes for the breakdown of glycans (i.e., five to 10 times more GHs than the number of GTs). The number of genes that encode GBPs is more difficult to define because many have other functional domains and have not been annotated as GBPs. A conservative estimate is that mammalian genomes encode 100 to 200 GBPs.
As genomes of new organisms become available, their sequences are routinely searched for genes that show similarity to known GTs, GHs, or GBPs. If a new gene is not annotated, the sequence can be used to find annotated genes with related sequences, either in the same species or across phylogeny, and this provides a base for inferring the biochemical activity of the encoded protein. The sequence of a new gene can also be analyzed for additional encoded motifs such as signal peptides, transmembrane domains, glycosylphosphatidylinositol (GPI) anchors (Chapter 12), or carboxy-terminal retrieval sequences. The GTs are among the most versatile category of proteins known in terms of the substrates they recognize. Thus, although it is difficult to predict the reaction catalyzed by a GT or GH on the basis of its sequence homology with a related GT or GH sequence, it is often possible to predict the anomeric linkage of the sugar transferred or hydrolyzed, respectively. Prokaryotic GHs have similarities to those of eukaryotes, and with some exceptions, prokaryotic and eukaryotic GTs have one of two folds, GT-A and GT-B, indicating two ancestors for essentially all GTs.
GENE FAMILIES
Glycosyltransferase (GT) and Glycoside Hydrolase (GH) Families
Carbohydrate-active enzymes can be classified according to several criteria. Substrate specificity forms the simplest basis to assign an Enzyme Commission (EC) number by the International Union of Biochemistry and Molecular Biology (IUBMB). GHs are given the code EC 3.2.1.x, where x represents substrate specificity. Similarly, GTs are described as EC 2.4.y.z, where y defines the sugar transferred and z describes the precise donor and acceptor. The EC number is given only after experimental determination of enzymatic specificity. Thus, only about 330 GT and GH enzymes currently have an EC number from the IUBMB.
The intrinsic problem with a classification system based on substrate (or product) specificity is that it does not appropriately accommodate enzymes that act on several substrates. It also fails to reflect the sequence or the structural features of these enzymes. To circumvent these problems, a novel system was introduced for classifying GHs and GTs on the basis of the relationship between amino acid sequence and folding similarities. Regardless of activity and substrate specificity, sequences that display similarity are grouped in the same family. For GTs, classification was initiated in 1997 (approximately 500 sequences; 27 families). This classification is continuously updated in the CAZy database, which listed approximately 260,000 GT sequences in approximately 100 families in August 2016. CAZy gives access to the various families of GTs, GHs, polysaccharide lyases, and their carbohydrate-binding modules, as well as several families of auxiliary activities, such as the recently described lytic polysaccharide monooxygenases. Each CAZy family is annotated with known enzyme activities and includes catalytic and structural features. This summary is followed by a list of the proteins and open reading frames (ORFs) belonging to each family, with links to sequence and structural information available in public databases. CAZy features summary pages for approximately 5000 publicly available genomes.
The earliest observation from the sequence-based families was that many families are “polyspecific” and contain enzymes of different substrate specificity. Polyspecific families indicate that (1) the acquisition of new specificities by GHs and GTs is a common evolutionary event, (2) their substrate specificities can be engineered for experimental or applied purposes, and (3) their substrate (or product) specificities are governed by fine details of three-dimensional structure, not by global fold. Human GTs with experimentally determined activities, are compiled in several excellent resources at Kyoto Encyclopedia of Genes and Genomics (KEGG) and Functional Glycomics Gateway. In contrast, assignments for other organisms, like microbes, are often erroneous, because of misassignment of EC numbers based on distant sequence relatedness. The challenge of the postgenomic era is therefore to dissect this ever-growing list of ORFs whose encoded proteins are candidate GTs of unknown donor, acceptor, and product specificities.
Glycan-Binding Proteins (GBPs)
The information presented by the wide variety of glycans on glycoconjugates is deciphered by an equally versatile number of GBPs that recognize specific sugars or glycans (Chapters 28–38). To understand the biology behind protein–glycan interactions, it is imperative to identify all of the GBPs and their glycan ligands.
GBPs were identified in the past by systematic biochemical studies that determined their glycan-recognition properties. However, the recent explosion of sequenced genomes makes it possible to identify genes likely to encode GBPs by sequence similarity. For example, the mannose-binding lectins (MBLs) can easily be identified because they show motifs found in C-type lectins (Chapter 34), as well as a collagen-like domain that promotes their oligomerization and is necessary for host defense through complement activation. A variant allele with changes in both the promoter and structural regions of the human MBL gene (MBL2) influences the stability and serum concentration of the protein. Epidemiological studies have suggested that genetically determined variations in MBL serum concentration influence the susceptibility to, and the course of, different types of infections, autoimmune reactions, and metabolic and cardiovascular diseases. The fact that genetic variations in MBL are frequent indicates a dual role for MBL in host defense and highlights the power of genomics to aid our understanding of human disease.
Most of the studies on GBPs have been restricted to mammalian proteins (e.g., C-type lectins, galectins, and Siglecs), and their counterparts in plants and other “lower” organisms are underexplored. An extended classification of GBPs is proposed in Chapter 28, where they are contrasted with binding proteins that recognize sulfated glycosaminoglycans (which seem to have emerged independently of each other, by convergent evolution).
Knowledge of the ligand specificity of a GBP is required to assign in vivo functions. In cases in which there is a dearth of information, rational predictions based on the framework and sequence of existing carbohydrate-recognition domains (CRDs) have been found useful. Legume lectins represent a class of GBPs identified decades ago that continues to provide perhaps the best model for protein–glycan recognition. Moreover, discovery of the legume lectin fold (jelly-roll motif) in mammalian lectins, such as galectins (Chapter 36), calnexin, and calreticulin (Chapter 34), highlights the preeminence of this fold in carbohydrate recognition across phylogeny. Earlier work in the identification of monosaccharide-binding specificities of legume lectins provided the framework for finding their relatives in all forms of life (Chapter 32). This approach led to the assignment of glycan specificities for proteins involved in the sorting of vesicular compartments, and in glycoprotein folding in the endoplasmic reticulum (ER) and Golgi compartments of mammalian cells (Chapter 39). Of similar importance is the discovery of new galectins in the galectin-10 family and galectin-like proteins in genome databases using similarity searches (Chapter 36). Likewise, Siglecs, a family of sialic acid–binding I-type lectins involved in regulating multiple biological responses (Chapter 35), show signature sequence motifs, and 17 members have been identified in primates to date. It is important to note that the mere presence of a CRD does not necessarily translate into functional glycan-recognizing activity. This is because sequence motifs used to identify CRDs often end up in a functionally inactive, lectin-like, CRD fold (Chapter 34).
Glycan microarrays provide a high-throughput means of detecting the interactions of GBPs with the diverse oligosaccharide sequences of glycoproteins, glycolipids, and polysaccharides (Chapter 30). The use of glass slides, microarray printing technology, and surface patterning of engineered glycophages displaying unique carbohydrate epitopes allows the production of glycan microarrays with the potential to examine binding of all types of GBPs (lectins, antiglycan monoclonal or serum antibodies, and glycan-binding cytokines or chemokines) to several thousand unique glycans, simultaneously. Binding is assessed by fluorescent or spectrometric techniques. Cross-platform comparisons and several Web-based resources like GlycoPattern enable analysis of array data for functional genomics. However, arrays that use different linkers and/or different attachment chemistries can give quite variable results, and the results need to be evaluated in the context of natural binding phenomena.
THE GLYCOME IN VARIOUS ORGANISMS
Viruses
It has long been known that many viruses use host glycans as specific binding receptors for entering the cell (Chapter 37). Similarly, several viruses encode lytic enzymes that break down host cell surface glycans to release viral particles after viral replication. Genome sequencing reveals that many double-stranded DNA viruses also take advantage by adding sugars to host glycoproteins through the use of viral GTs (Chapter 42). Although the biological role of viral GTs is poorly understood, in several cases a function has been identified. For example, the T4 bacteriophage encodes nucleases that degrade host cell DNA. To protect its own genome, the phage modifies its DNA by replacing cytosine with 5-hydroxymethylcytosine and subsequently transferring glucose (Glc) to the 5-hydroxymethylcytosine using a specific UDP-Glc:DNA Glc-transferase. The baculovirus enzyme ecdysteroid glucosyltransferase (EGT) disrupts the hormonal balance of the insect host by catalyzing the conjugation of ecdysteroid hormones with Glc or galactose (Gal). Expression of the EGT gene allows the virus to block molting and pupation of infected insect larvae. Similarly, Chloroviruses have enzymes in CAZy family GT4 for the glycosylation of their structural proteins. Serotype conversion in Shigella flexneri is mediated by temperate bacteriophages, which encode GTs that mediate O-antigen conversion by the addition of Glc to O-antigen units. Finally, giant viruses such as Acanthamoeba polyphaga mimivirus with the largest known viral genome (∼1.2 Mb), produces a glycosylation machinery with 12 putative GTs for the synthesis of complex O-glycans.
Bacteria
Bacterial GTs play a major role in their symbiosis and their virulence. Some bacteria such as Campylobacter are able to N-glycosylate their proteins, but the most universal role for bacterial glycosylation is in the synthesis of cell-wall peptidoglycan, simple glycolipids, lipopolysaccharides and complex exopolysaccharides (Chapter 21). The GTs involved in peptidoglycan biosynthesis are GT28 MurG, which adds N-acetylglucosamine (GlcNAc) to undecaprenyl diphospho-N-MurNAc, and GT51, which polymerizes undecaprenyl diphospho-MurNAc-GlcNAc. Mycobacterium tuberculosis produces an extremely complex envelope that includes all of the above. In bacteria, the role of these glycans is to provide a barrier that affords mechanical, chemical, and biological protection to the cell. Some pathogenic or commensal bacteria produce an outer glycan layer that mimics that of their hosts, in order to evade host immune surveillance (Chapters 15 and 42). Pasteurella multocida produces a thick hyaluronan capsule. Oral Streptococci produce two GTs for adhesion and virulence, and the EPax gene GT enables colonization of the gut by Enterococcus faecalis. Other pathogens such as Escherichia coli K1 and Neisseria meningitidis produce a polyα2–8 sialic acid capsule. It is thought that mammalian gut bacteria produce capsular polysaccharides that help the maturation of the host immune system.
Archaea
Archaea devote ∼1% of their genes to GTs but, on average, devote only 0.25% to GHs, and there is almost no correlation with the number of GH genes and the overall number of genes. Surprisingly, ∼20% of sequenced archaeal genomes appear to be completely devoid of GHs. The most striking example is Methanosphaera stadtmanae, whose genome encodes at least 43 GTs but apparently no GHs. This is not due to sequence divergence, because GHs are readily detected in some Archaea. These observations suggest that (1) horizontal transfer is likely the determining factor behind archaeal GH repertoires, and (2) the Archaea in question do not recycle glycosidic bonds elaborated by their own GTs. Although they do not make peptidoglycans like bacteria, Archaea use nucleotide-activated oligosaccharides to produce a variety of extracellular polysaccharides such as the heteropolysaccharide “methanochondroitin” made by Methanosarcina barkeri, which resembles eukaryotic chondroitin sulfate (Chapter 17). Archaea also make glycophospholipids and one relevant GT is GDP-Glc:glucosyl-3-phosphoglycerate synthase from family GT81 in Methanococcoides burtonii. In CAZy family GT55, there are several archaeal GDP-Man:mannosyl-3-phosphoglycerate synthases. A number of Archaea have GTs related to bacterial and eukaryotic oligosaccharyltransferases (CAZy family GT66), which is consistent with the fact that Archaea use oligosaccharyldiphospholipids as sugar donors. It has been shown that the archaeon Methanococcus voltae uses this strategy to transfer N-glycans to flagellin and S-layer proteins. Like bacteria and eukaryotes, evolution toward an obligate symbiont lifestyle was also accompanied by gene loss in Archaea. For example, the tiny genome of Nanoarchaeum equitans appears to encode only three GTs and no GHs.
EUKARYOTES
With their large genomes and complex body plans that require different gene expression in various tissues and/or at different developmental stages, genomes of eukaryotes encode many more GTs and GHs than those of individual bacteria and Archaeal species. But, overall, prokaryotes appear to use a greater diversity of the monosaccharides that exist in nature (Chapters 20–23). Several eukaryotes have also undergone genome reduction and lost most of their GT genes. Thus, Plasmodium falciparum and Encephalitozoon cuniculi have only nine and eight GTs, respectively. Overall, the abundance of GTs in free-living eukaryotes correlates with evolution to multicellularity. Free-living fungi and the unicellular marine green alga Ostreococcus tauri have a number of GTs similar to certain bacteria.
Plants
The genomes of “higher” plants encode more GTs than any other organism, with approximately 560 in Arabidopsis, approximately 613 in rice, and approximately 740 in poplar! “Higher” plants have huge genomes resulting from several rounds of complete genome duplication. The massive number of GTs in plants is due to the expansion of several extremely populated GT families. For example, Arabidopsis, rice, and poplar have about 120, 200, and 300 GT1 genes, respectively. “Higher” plants are characterized by extremely complex cell walls made of various polysaccharides that can be rather simple like cellulose, more complex as in hemicelluloses (e.g., xylans, glucuronoxylans, galactomannans, xyloglucans), or extremely complex like the “hairy” regions of pectin (Chapter 24). Biosynthesis of pectin alone requires the action of dozens of GTs. Differential expression in various tissues is probably one of the driving forces behind the accumulation of hundreds of genes encoding GTs in plants. Likewise, a diverse array of GHs are involved in the remodeling of the plant cell wall during plant growth. Thus, Arabidopsis, rice, and poplar genomes encode about 400, 420, and 600 GHs, respectively.
Vertebrates
Although they do not encode an enormous number of GT genes like plants, vertebrates are characterized by a large diversity of GT genes. Human GTs fall into 43 CAZy families, a number similar to that of plants. Families that are present only in vertebrates are GT6, GT12, and most GT29 family members (invertebrates have only one member of a particular sialyltransferase subfamily, whereas vertebrates usually have many different GT29 sialyltransferases belonging to several distinct subfamilies). However, there are no GT families that are unique to humans or primates. The completion of the first animal genomes also revealed a relative paucity in the number of encoded GHs. Thus, the human genome codes for only about 100 GHs, with only a dozen devoted to the digestion of only three glycans: sucrose, lactose, and a portion of starch. The digestion of the immense majority of the plant cell-wall polysaccharides in the diet is “outsourced” to the multitude of different microorganisms that colonize the human gut. The genetic material of this flora, the “microbiome,” greatly enlarges our limited genome. For instance a single species of our gut bacteria such as Bacteroides cellulosilyticus WH2 encodes about four times more GHs (373) than our genome.
Invertebrates
One of the initial surprises that came with the completion of the first genomes was that the human genome encodes fewer GTs (236) than that of the nematode Caenorhabditis elegans (272). Drosophila melanogaster has only 151 GT genes. These gross numbers, however, mask important biological differences. The comparative abundance of GTs in C. elegans compared with humans is essentially due to four GT families more highly represented in the nematode: GT1 glucuronyltransferases (78 in C. elegans, 35 in human), GT11 fucosyltransferases (26 in C. elegans, 3 in human), GT14 β-xylosyl-transferases and β1-6 GlcNAc-transferases (20 in C. elegans, 11 in human), and GT92 (26 in C. elegans, 0 in human). For most other GT families, C. elegans appears to have the same number or fewer GT genes than humans. With more than 400 GT genes, the bdelloid rotifer Adineta vaga is the animal with the largest known number of GTs. This large number is due to the ameiotic reproduction mode of this animal, which is accompanied by a large rate of horizontal gene acquisition from other organisms. C. elegans has nearly 112 GHs, whereas D. melanogaster has 104 and humans have 100. GH18 chitinase is highly represented in C. elegans and D. melanogaster with 43 and 22 members, respectively.
MODULAR GLYCOSYLTRANSFERASES AND GLYCOSIDE HYDROLASES
In addition to catalytic specificity, the amino acid sequence of some GTs and GHs can also contain one or more additional domains that modulate the activity of the GT or GH. The most striking example is the two-domain mammalian heparan synthases that have evolved for the addition of alternating sugars to form a polysaccharide (Chapters 16 and 17). The amino-terminal domain, which adds β1-4 glucuronic acid (GlcA) residues, belongs to GT47, whereas the carboxy-terminal domain, which adds α1-4 GlcNAc residues, belongs to GT64. Some strains of bacteria have a heparan synthase, which also consists of two catalytic modules, from families GT2 and GT45 (Figure 8.1), thereby providing a beautiful example of convergent evolution. A similar example of convergent evolution is found among chondroitin synthases, in which human enzymes are made of GT31 and GT7 catalytic domains, whereas the bacterial equivalent is made of tandem GT2 catalytic domains. Human LARGE is another bifunctional glycosyltransferase made of two domains. The amino-terminal domain, which adds α1-3 xylose (Xyl) residues, belongs to GT8, whereas the carboxy-terminal domain, which adds β1-3 GlcA residues, belongs to GT49.
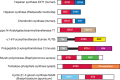
FIGURE 8.1.
Schematic examples of modular GTs (glycosyltransferases). GT family modules are shown in red and blue. Other modules in various colors are CBM13, ricin-like carbohydrate-binding module; SH3, src homology domain 3; X84, putative glycan-binding module; (more...)
Other modular GTs can feature an appended GBP domain. The best-known examples are polypeptide N-acetylgalactosaminyltransferases (ppGalNAcTs; GALNT) that transfer N-acetylgalactosamine (GalNAc) to Ser or Thr residues (Chapters 6 and 10). In these enzymes, a GT27 catalytic domain is linked to a GBP domain related to ricin and classified as CBM13 in the CAZy database. The GBP domain binds to the GalNAc residue transferred to protein by the GT27 catalytic domain and tethers the enzyme to the substrate. Another example is mouse polypeptide β-xylosyltransferase 2, in which a GT14 catalytic domain is linked to a carboxy-terminal domain that is thought to act as a GBP.
The GHs can also be modular, with the catalytic module appended to one or more other modules whose role is to bind polysaccharides. Although human GHs are infrequently modular, those of microbes involved in plant cell-wall degradation can have more than five different modules assembled in a single polypeptide. Human acidic chitinase is an example of a mammalian modular GH having a CBM14 domain appended at the carboxyl terminus of the GH18 catalytic domain. The most intricate architecture of GHs is found in certain environmental bacteria, such as Clostridium thermocellum, which elaborate a macromolecular complex called a “cellulosome” in which a large variety of modular plant cell-wall hydrolases are assembled together on a scaffolding protein. This strategy enables the assembly of dozens of catalytic modules simultaneously targeting the various polysaccharides that make up the plant cell wall.
RELATIONSHIPS OF GENOMICS TO GLYCOMICS
In summary, the genome comprises the DNA of an organism, and it therefore includes all the genes that produce the glycome, which represents all of the glycans made by an organism. Although within an organism, almost every cell that contains a nucleus and mitochondria has an identical genome, cells typically differ in the portion of the glycome they express. Thus, their glycan complement depends on which genes are actively transcribed and which transcripts are translated and stably expressed in a particular cell type. Transcription, splicing, translation, and posttranslational processing may vary depending on the state of differentiation and physiological environment of a cell. Therefore, during development and differentiation or under different environmental conditions, the glycan repertoire of a cell represents a subset of all the glycans that an organism is capable of making. To describe this variation, it is common to qualify the term glycome when referring to the glycans made by a particular tissue or cell type (e.g., T-cell glycome, hepatocyte glycome, or serum glycome) and to note the particular stage of growth (e.g., fetal liver glycome and breast cancer serum glycome). This is because the glycome of a given cell in a given species can undergo substantial changes in response to environmental stimuli ranging from pH and ionic strength to hormonal stimulation or inflammation. Combined with the “assembly-line” nature of the Golgi apparatus (Chapter 4) and potential remodeling by GHs, full knowledge of the GT transcriptome is often a poor predictor of the actual glycome of a given cell type, and there is currently no substitute for carrying out glycomic and glycoproteomic analysis (Chapter 51).
ACKNOWLEDGMENTS
The authors appreciate helpful comments and suggestions from Wu Di, Anabel Gonzelez-Gil, and Shweta Varshney.
Footnotes
- 1
“CAZy database,” “Kyoto Encyclopedia of Genes and Genomics,” “Functional Glycomics Gateway,” and “National Center for Biotechnology Information” refer to online resources that can be linked directly from the online version of this chapter.
FURTHER READING
- Raman R, Raguram S, Venkataraman G, Paulson JC, Sasisekharan R. 2005. Glycomics: An integrated systems approach to structure–function relationships of glycans. Nat Methods 2: 817–824. [PubMed: 16278650]
- Mitra N, Sinha S, Ramya TN, Surolia A. 2006. N-linked oligosaccharides as outfitters for glycoprotein folding, form and function. Trends Biochem Sci 31: 156–163. [PubMed: 16473013]
- Gupta G, Surolia A. 2007. Collectins: Sentinels of innate immunity. Bioessays 29: 452–464. [PubMed: 17450595]
- Lairson LL, Henrissat B, Davies GJ, Withers SG. 2008. Glycosyltransferases: Structures, functions, and mechanisms. Annu Rev Biochem 77: 521–555. [PubMed: 18518825]
- El Kaoutari A, Armougom F, Gordon JI, Raoult D, Henrissat B. 2013. The abundance and variety of carbohydrate-active enzymes in the human gut microbiota. Nature Rev Microbiol 11: 497–504. [PubMed: 23748339]
- Lombard V, Golaconda Ramulu H, Drula E, Coutinho PM, Henrissat B. 2014. The Carbohydrate-Active Enzymes database (CAZy) in 2013. Nucleic Acids Res 42: D490–D495. [PMC free article: PMC3965031] [PubMed: 24270786]
- Kohler A, Kuo A, Nagy LG, Morin E, Barry KW, Buscot F, Canback B, Choi C, Cichocki N, Clum A, et al. 2015. Convergent losses of decay mechanisms and rapid turnover of symbiosis genes in mycorrhizal mutualists. Nat Genet 47: 410–415. [PubMed: 25706625]
- Review A Genomic View of Glycobiology.[Essentials of Glycobiology. 2009]Review A Genomic View of Glycobiology.Henrissat B, Surolia A, Stanley P. Essentials of Glycobiology. 2009
- Review A Genomic View of Glycobiology.[Essentials of Glycobiology. 2022]Review A Genomic View of Glycobiology.Terrapon N, Henrissat B, Aoki-Kinoshita KF, Surolia A, Stanley P. Essentials of Glycobiology. 2022
- Review Cracking the "Sugar Code": A Snapshot of N- and O-Glycosylation Pathways and Functions in Plants Cells.[Front Plant Sci. 2021]Review Cracking the "Sugar Code": A Snapshot of N- and O-Glycosylation Pathways and Functions in Plants Cells.Strasser R, Seifert G, Doblin MS, Johnson KL, Ruprecht C, Pfrengle F, Bacic A, Estevez JM. Front Plant Sci. 2021; 12:640919. Epub 2021 Feb 19.
- Review The Astounding World of Glycans from Giant Viruses.[Chem Rev. 2022]Review The Astounding World of Glycans from Giant Viruses.Speciale I, Notaro A, Abergel C, Lanzetta R, Lowary TL, Molinaro A, Tonetti M, Van Etten JL, De Castro C. Chem Rev. 2022 Oct 26; 122(20):15717-15766. Epub 2022 Jul 12.
- Review A genetic approach to Mammalian glycan function.[Annu Rev Biochem. 2003]Review A genetic approach to Mammalian glycan function.Lowe JB, Marth JD. Annu Rev Biochem. 2003; 72:643-91. Epub 2003 Mar 27.
- A Genomic View of Glycobiology - Essentials of GlycobiologyA Genomic View of Glycobiology - Essentials of Glycobiology
Your browsing activity is empty.
Activity recording is turned off.
See more...