Only when the structure of DNA was discovered in the early 1950s did it become clear how the hereditary information in cells is encoded in DNA's sequence of nucleotides. The progress since then has been astounding. Fifty years later, we have complete genome sequences for many organisms, including humans, and we therefore know the maximum amount of information that is required to produce a complex organism like ourselves. The limits on the hereditary information needed for life constrain the biochemical and structural features of cells and make it clear that biology is not infinitely complex.
In this chapter, we explain how cells decode and use the information in their genomes. We shall see that much has been learned about how the genetic instructions written in an alphabet of just four “letters”—the four different nucleotides in DNA—direct the formation of a bacterium, a fruitfly, or a human. Nevertheless, we still have a great deal to discover about how the information stored in an organism's genome produces even the simplest unicellular bacterium with 500 genes, let alone how it directs the development of a human with approximately 30,000 genes. An enormous amount of ignorance remains; many fascinating challenges therefore await the next generation of cell biologists.
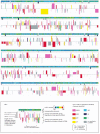
The problems cells face in decoding genomes can be appreciated by considering a small portion of the genome of the fruit fly Drosophila melanogaster (). Much of the DNA-encoded information present in this and other genomes is used to specify the linear order—the sequence—of amino acids for every protein the organism makes. As described in Chapter 3, the amino acid sequence in turn dictates how each protein folds to give a molecule with a distinctive shape and chemistry. When a particular protein is made by the cell, the corresponding region of the genome must therefore be accurately decoded. Additional information encoded in the DNA of the genome specifies exactly when in the life of an organism and in which cell types each gene is to be expressed into protein. Since proteins are the main constituents of cells, the decoding of the genome determines not only the size, shape, biochemical properties, and behavior of cells, but also the distinctive features of each species on Earth.
Schematic depiction of a portion of chromosome 2 from the genome of the fruit fly Drosophila melanogaster. . This figure represents approximately 3% of the total Drosophila genome, arranged as six contiguous segments. As summarized in the key, the symbolic (more...)
One might have predicted that the information present in genomes would be arranged in an orderly fashion, resembling a dictionary or a telephone directory. Although the genomes of some bacteria seem fairly well organized, the genomes of most multicellular organisms, such as our Drosophila example, are surprisingly disorderly. Small bits of coding DNA (that is, DNA that codes for protein) are interspersed with large blocks of seemingly meaningless DNA. Some sections of the genome contain many genes and others lack genes altogether. Proteins that work closely with one another in the cell often have their genes located on different chromosomes, and adjacent genes typically encode proteins that have little to do with each other in the cell. Decoding genomes is therefore no simple matter. Even with the aid of powerful computers, it is still difficult for researchers to locate definitively the beginning and end of genes in the DNA sequences of complex genomes, much less to predict when each gene is expressed in the life of the organism. Although the DNA sequence of the human genome is known, it will probably take at least a decade for humans to identify every gene and determine the precise amino acid sequence of the protein it produces. Yet the cells in our body do this thousands of times a second.
The DNA in genomes does not direct protein synthesis itself, but instead uses RNA as an intermediary molecule. When the cell needs a particular protein, the nucleotide sequence of the appropriate portion of the immensely long DNA molecule in a chromosome is first copied into RNA (a process called transcription). It is these RNA copies of segments of the DNA that are used directly as templates to direct the synthesis of the protein (a process called translation). The flow of genetic information in cells is therefore from DNA to RNA to protein (). All cells, from bacteria to humans, express their genetic information in this way—a principle so fundamental that it is termed the central dogma of molecular biology.
The pathway from DNA to protein. The flow of genetic information from DNA to RNA (transcription) and from RNA to protein (translation) occurs in all living cells.
Despite the universality of the central dogma, there are important variations in the way information flows from DNA to protein. Principal among these is that RNA transcripts in eucaryotic cells are subject to a series of processing steps in the nucleus, including RNA splicing, before they are permitted to exit from the nucleus and be translated into protein. These processing steps can critically change the “meaning” of an RNA molecule and are therefore crucial for understanding how eucaryotic cells read the genome. Finally, although we focus on the production of the proteins encoded by the genome in this chapter, we see that for some genes RNA is the final product. Like proteins, many of these RNAs fold into precise three-dimensional structures that have structural and catalytic roles in the cell.
We begin this chapter with the first step in decoding a genome: the process of transcription by which an RNA molecule is produced from the DNA of a gene. We then follow the fate of this RNA molecule through the cell, finishing when a correctly folded protein molecule has been formed. At the end of the chapter, we consider how the present, quite complex, scheme of information storage, transcription, and translation might have arisen from simpler systems in the earliest stages of cellular evolution.