
 1.
1.Copyright Notice
All rights reserved.
The author grants the U.S. National Library of Medicine permission to archive and post a copy of this paper on the Journal Article Tag Suite Conference proceedings website.
Bookshelf ID: NBK189779

An official website of the United States government

NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
Journal Article Tag Suite Conference (JATS-Con) Proceedings 2013/2014 [Internet]. Bethesda (MD): National Center for Biotechnology Information (US); 2014.
The JATS preview stylesheets are written in XSLT 1.0. This paper describes approaches used when customizing the XSLT 1.0 stylesheets for use with reports from a government body, when adapting the stylesheets for XSLT 2.0 for processing articles for an online journal, and upgrading the stylesheets to XSLT 3.0 as a testbed for XSLT 3.0 techniques.
The XSLT 1.0 “NISO Journal Article Tag Suite (JATS) version 1.0” stylesheets from the National Center for Biotechnology Information at the U.S. National Library of Medicine (NLM) are available on GitHub. The stylesheets are provided “as a point of entry for JATS users who may not have the resources to create them from scratch.” In particular, the stylesheets’ maintainers “view these stylesheets as a template for a customized solution, not the solution itself" and explicitly don't accept changes to do with customizing the presentation.
Despite that, the stylesheets are a useful first step towards using XSLT with JATS in a production system, and this paper describes the experience of using the stylesheets with XSLT 1.0, 2.0, and 3.0.
When sticking with XSLT 1.0, the best approach can be to try to leave the original stylesheet untouched as much as possible and to, instead, write a customization stylesheet that imports the original stylesheets and overrides template rules in the original as necessary to achieve the correct format output. Inevitably, there are some parts of the original that need more that just overriding, and this paper covers the changes that had to be made on that project.
When adapting the stylesheets for use with XSLT 2.0, it is possible to go a long way with just changing the 'version' attribute and processing with a XSLT 2.0 processor, but the extra features of XSLT 2.0 – such as being able to pass sequences of attribute nodes as template parameters – give more scope for being able to customise the output. Given that, it is preferable to make changes to the original stylesheets as needed, rather than adopting the hands-off approach used with the XSLT 1.0 project. This paper details the XSLT 2.0-specific changes made when customising the stylesheets to process journal articles.
XSLT 3.0 is a whole new ball game, and the XSLT 3.0 testbed project on GitHub is a public, medium-sized XSLT 3.0 project where people could try out new XSLT 3.0 features on the transformations to (X)HTML(5) and XSL-FO that are what we do most often and, along the way, maybe come up with new design patterns for doing transformations using the higher-order functions, partial function application, and other goodies that XSLT 3.0 gives us. The project started from the JATS Preview stylesheets since they were neither too large to be manageable nor too small to be realistic. This paper discusses the current changes and possible benefits of applying XSLT 3.0 features to the JATS Preview stylesheets.
The XSLT 1.0 “NISO Journal Article Tag Suite (JATS) version 1.0” stylesheets [[5]] from the National Center for Biotechnology Information (NCBI) [[6]] at the U.S. National Library of Medicine (NLM) [[7]] are available on GitHub. The stylesheets are provided “as a point of entry for JATS users who may not have the resources to create them from scratch.”.
The complete package includes XSLT stylesheets for transforming JATS to HTML and to XSL-FO for formatting to PDF, etc., plus a range of XSLT stylesheets and XProc pipelines for pre- and post-processing for things such as converting from OASIS tables to HTML tables, massaging different citation formats so they can be handled by the preview stylesheets, and optimizing outputs for different media. None of the projects covered here have needed any of those pre- or post-processing steps, so they aren’t covered in this paper.
There are several reasons why the JATS Preview stylesheets, which are dated 2012, are written in XSLT 1.0 even though XSLT 2.0 became a W3C Recommendation in 2007:
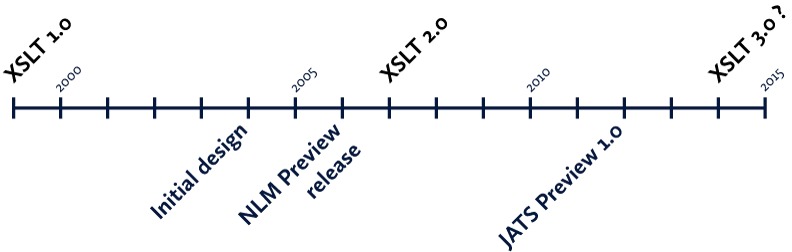
Timeline for stylesheet development reconstructed from comments in code, downloads, and emails with Kim Tryka of NCBI and B. Tommie Usdin of Mulberry Technologies
The JATS Preview stylesheets, and the earlier NLM stylesheets, were developed for NCBI by Mulberry Technologies, Inc.
The stylesheet’s output veers towards the functional side of stylish, as shown in Fig. 2.

Draft of this paper formatted with core JATS Preview stylesheets
The maintainers of the JATS Preview stylesheets have an explicit policy against introducing more support for customizing the output from the stylesheets (emphasis added):
These stylesheets are provided as a point of entry for JATS users who may not have the resources to create them from scratch. Because there are many varied implementations of JATS, you should have no expectation that these stylesheets will create production ready files in any arbitrary system. Instead, the stylesheets should be customized for your particular needs.
Because we view these stylesheets as a template for a customized solution, not the solution itself, we will accept changes that fix an actual bug, but we will not merge in changes that we view as “customization”. For example, we will accept changes that fix a problem which otherwise leads to failure in creating a final output file, but we will not accept changes that focus on presentational aspects of the final output (such as font changes, margin changes, graphics sizing, etc).
This contrasts with other standard document types such as DocBook [[17]] and TEI [[19]] that provide standard stylesheets supporting [[18]], e.g., “several hundred things you can set to change the output in various formats” [[20]].
Deliberately not supporting every possible style permutation hasn’t precluded the JATS Preview stylesheets from supporting other people customizing the stylesheets nor does it stop you from using the stylesheets as a base for customized output. The quote, above, from the project’s page on GitHub indicates the maintainers’ expectation that people will use the provided stylesheets as the base for customization, plus there’s aspects both of how XSLT works and of how the stylesheets were written that make it easy to customize them.
Three aspects in particular of the design of XSLT support customization efforts: support for modular stylesheets; organization as templates; and named attribute sets.
Support for modular stylesheets has been part of XSLT since the xsl:include and xsl:import top-level elements in XSLT 1.0. Even if you haven’t come across them before, you would expect from their names that they have something to do with using one stylesheet file as part of another. xsl:include does, indeed, conceptually include the contents of one stylesheet inside another, while xsl:import makes the contents of the imported stylesheet available to the importing stylesheet with well-defined rules about the “import precedence” of the content of importing stylesheets over that of imported stylesheets.
The core JATS Preview stylesheets use only xsl:include, as shown in Fig. 3.
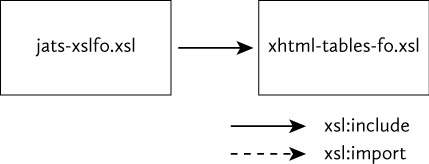
Imports and includes in JATS Preview stylesheets
The organization of XSLT stylesheets as predominately xsl:template rules that match on particular contexts in the source document makes it easy to write an importing stylesheet containing templates matching specific contexts. For example, the following template is used for processing td elements: the literal fo:table-cell is copied to the result and the xsl:call-tempate, like all elements in the XSLT namespace, is acted on by the XSLT processor.
<xsl:template match="td">
<fo:table-cell xsl:use-attribute-sets="td">
<xsl:call-template name="process-table-cell"/>
</fo:table-cell>
</xsl:template>The rules on import precedence make it easy for a customization to override the corresponding templates in the core JATS Preview stylesheets. That doesn’t mean that overriding templates is the ideal mechanism – for example, if you want to make a small change to what’s currently a large complex template, you generally have to maintain a copy of the large template with your changes added rather than being able to reach into and override just a small part of the original template – but overriding imported templates works well in the general case.
A named attribute set is a group of attribute definitions that are evaluated afresh each time they are used, and the resulting attributes are added to an element in the result of the XSLT transformation. The rules for combining multiple named attribute sets with the same name and for combining multiple different attribute sets make it easy for an importing stylesheet to augment or override the attribute sets in the core JATS Preview stylesheets.
Three aspects of the design of the JATS Preview stylesheets particularly support customization efforts: global variables for font-family, etc.; using named attribute sets; and using named templates. Arguably all of these would be present in the JATS Preview stylesheets irrespective of whether the stylesheets were intended to support customization since they embody the “Don’t Repeat Yourself” (DRY) principle [[21]] where “Every piece of knowledge must have a single, unambiguous, authoritative representation within a system”. For example:
As a method for organising a stylesheet, it eases maintenance, but it also eases customization since the authoritative representations can be overridden and/or reused in the customizing stylesheet.
For example, the XSLT 1.0 stylesheet described in the following section includes the following two named attribute set definitions and template:
<xsl:attribute-set name="td">
<xsl:attribute name="line-stacking-strategy">max-height</xsl:attribute>
</xsl:attribute-set>
<xsl:attribute-set name="td-small" use-attribute-sets="td">
<xsl:attribute name="line-height">10pt</xsl:attribute>
<xsl:attribute name="border">none</xsl:attribute>
<xsl:attribute name="padding-top">0pt</xsl:attribute>
<xsl:attribute name="padding-bottom">0pt</xsl:attribute>
</xsl:attribute-set>
<xsl:template match="td[ancestor::table[@style = 'small']]">
<fo:table-cell xsl:use-attribute-sets="td-small">
<xsl:call-template name="process-table-cell"/>
</fo:table-cell>
</xsl:template>The “td” named attribute set has a definition in the main JATS Preview stylesheets, so this definition adds to that definition, and the combined attribute set is evaluated whenever the “td” attribute set is used, for example, in the “td-small” named attribute set, which is used with tables that are to be formatted with closer spacing than usual. The template for a td in such a table uses that named attribute set, which adds all the attributes from the “td-small” attribute set and from all definitions of the “td” attribute set to the fo:table-cell in the result of the transformation. The template doesn’t do much else since it is possible to use the “process-table-cell” named template from the core JATS Preview Stylesheet to handle the common aspects of formatting a table cell.
For a 2012 project to format documents using a variation on JATS Blue markup to PDF, the customizations were developed as XSLT 1.0 stylesheets importing the core JATS Preview stylesheets since:
The formatted output retains some similarity to the JATS Preview stylesheets output, as shown in Fig. 4.

Draft of this paper formatted with XSLT 1.0 customization
Apart from fixing a typo in an variable name, the only changes were to set the end-indent property in ten templates where the core stylesheets already set the start-indent property. Modified copies of other templates were put in the customization stylesheet, but copying another ten templates, some comparatively large, just to add one property to each would have made the customization stylesheet larger, harder to understand, and harder to maintain for very little advantage.
By changing as little as possible, it should be easy to update the project’s copy of the core JATS Preview stylesheets whenever NCBI releases a new version.
The simplest, and usual, structure would be for the project’s customization stylesheet to import the core JATS Preview stylesheets, but as shown in Fig. 5, the project’s top-level stylesheet imports: two MathML-related stylesheets; the project’s customizations; and the core JATS Preview stylesheets. The two MathML-related stylesheets override both the customizations and the core styles to provide workarounds for two unrelated problems:
The workarounds are both simple, but they are implemented as separate stylesheets so removing each once they are no longer needed requires simply deleting the corresponding xsl:import in the top-level stylesheet. If the workarounds had been incorporated into the project’s customization, it would have resulted in fewer XSLT files, but it would also have been more work to undo each workaround.
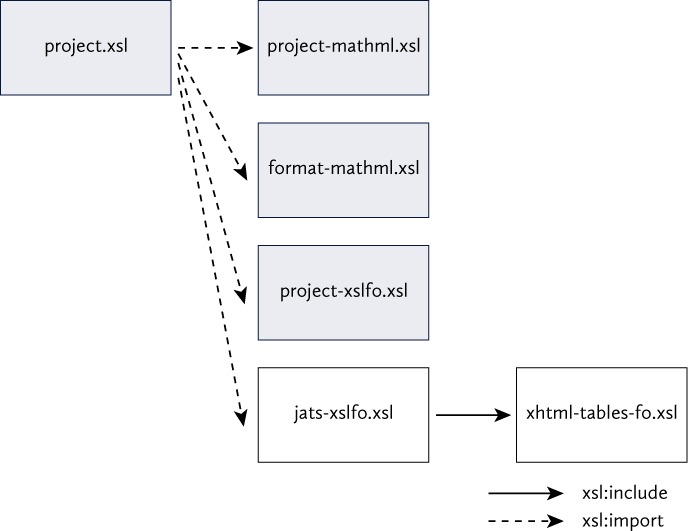
Imports in XSLT 1.0 customization
As shown in Fig. 6, in terms of lines of code, the main customization stylesheet comprised approximately:
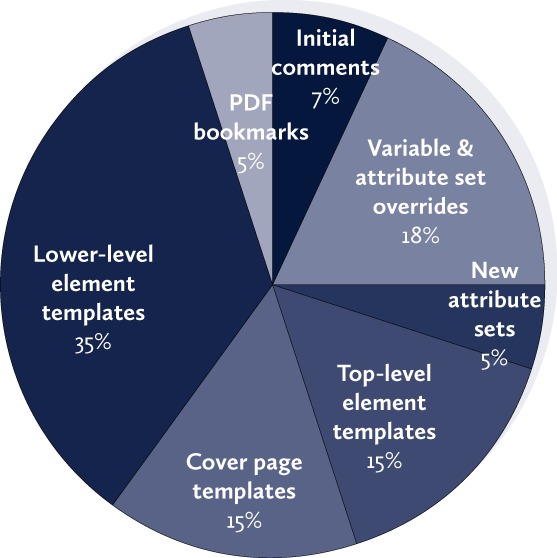
Composition of the XSLT 1.0 customization stylesheet
No vendor extensions were used in the XSLT processing.
The only vendor extension used in the XSL-FO processing was the MathML support. While you can reasonably expect that a XSL-FO formatter supports MathML, MathML isn’t required by the XSL 1.1, so strictly speaking the MathML support is a vendor extension.
PLOS ONE (PONE) [[24]] is an international, peer-reviewed, open-access, online publication published by PLOS (Public Library of Science) [[23]], a nonprofit publisher and advocacy organization headquartered in San Francisco, California, USA.
PLOS ONE receives manuscripts in Word, LaTeX, or RTF formats, then converts these to XML conforming to the NLM Journal Publishing DTD v3.0 prior to publication.
PLOS ONE articles are formatted in two-column pages. Figures may be either column-wide or page-wide, and tables may be column-wide, page-wide, or rotated so their width is page-high, but there is no size information for either figures or tables in the source XML. Figures and graphics may also float to either the top or bottom of the page or column.
For a 2013 project to replicate PLOS ONE’s existing house style [[25]] using XSL-FO, it was decided to modify the core stylesheets rather than use a customization stylesheet because:
Since the core stylesheets were to be extensively modified, they were upgraded to XSLT 2.0 because:
The formatted output has very little similarity to the JATS Preview stylesheets output, as shown in Fig. 7. The same result could have been achieved using only XSLT 1.0, but it was considered easier to do it with XSLT 2.0.

Draft of this paper formatted with XSLT 2.0 customization
XSL 1.1 defines a ‘before-float-reference-area’ on a page, but does not define an area for content floated to the ‘after’ end of the page, and the ‘before-float-reference-area’, when instantiated, takes the full width of the fo:region-body of the page.
PLOS therefore had to choose a XSL formatter based on the availability of vendor extensions to support more ways to float than defined by XSL 1.1.
The block diagram for processing PONE documents is shown in Fig. 8.
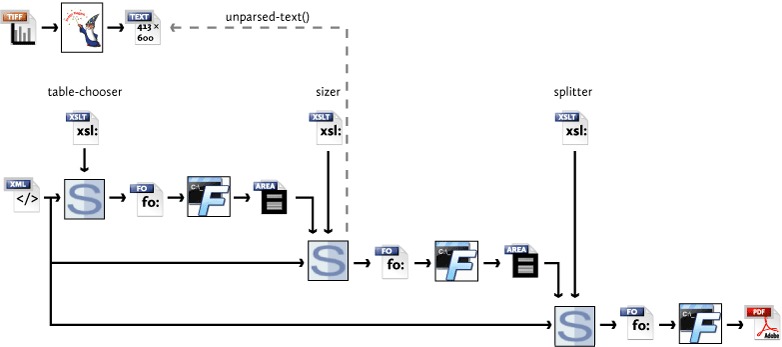
Processing block diagram
Graphics at least have an intrinsic size and, in formats such as TIFF, have an intrinsic resolution as well.
The process for determining whether graphics are column-wide or page-wide is:
The PLOS ONE authoring guidelines allow graphics sized up to the height of the page body, but figures may have captions of up to 300 characters, as well as having a label, title, and DOI that also appear in the formatted output. XSL doesn’t allow floated FOs to break across a page, so similarly to as described below for tables, the processing system ‘preformats’ the figure captions at both widths and writes out the area tree to be used as input by the main stylesheeet so the stylesheet reduces the allowed maximum height of the graphic so the graphic won’t push its following caption into the footer area.
Tables, as noted above, are presented one of three ways – column-wide, page-wide, or page-high – depending on which best fits the content of the table. Deciding which to do is entirely up to the processing system since the source XML, converted from other sources as it was, does not include even the few presentation-oriented attributes defined by the DTD.
The NLM/JATS DTDs support [[26]] specifying the orientation of a combined table and caption but do not provide a way to indicate the width of a table. The NISO JATS table model does allow a ‘style’ attribute on table and caption, but not on the table-wrap that contains them both.
The sample files provided at the start of the project included TIFF images of each of the tables in the samples as well as TIFF files for the graphics, and it wasn’t until the project was underway that it was made clear that the images of the tables were artifacts of the existing processing system and, not only were they not going to be available for new documents, the new system was expected to produce those as well.
The implemented approach makes a temporary ‘sizer’ formatted document containing each table at each width, saves the area tree from that document as XML, and provides the area tree as a parameter to the stylesheet that produces the FO for the final formatted output.
The ‘sizer’ document comprises three page sequences that each have a different fixed width and a large height (since the formatter doesn’t support fo:root media-usage="bounded-in-one-dimension">). Every table in the source XML has an ID, so the tables on each page are given a ID unique in their FO document by prefixing a page-specific prefix to each table’s original ID. Fig. 9 shows tables from an article formatted at page-wide, column-wide, and page-high widths. The first two tables fit within a column, but the third overflows a column but not the width of a page.

‘sizer’ document
The stylesheet that produces the ‘sizer’ document is very simple. A template matching the document node does all the work, and the stylesheet imports the ‘main’ stylesheet so the tables are formatted exactly as they would be in the final output. Since there are only three page types, the stylesheet does not even define any page-sequence masters, so each fo:page-sequence refers directly to a fo:simple-page-master.
<fo:root>
<fo:layout-master-set>
<xsl:call-template name="define-sizer-simple-page-masters"/>
</fo:layout-master-set>
<fo:page-sequence master-reference="page-wide">
<fo:flow flow-name="body" xsl:use-attribute-sets="fo:flow">
<xsl:apply-templates select="//table-wrap">
<xsl:with-param name="prefix" select="'page-wide-'" as="xs:string" tunnel="yes" />
</xsl:apply-templates>
</fo:flow>
</fo:page-sequence>
<fo:page-sequence master-reference="column-wide">
<fo:flow flow-name="body" xsl:use-attribute-sets="fo:flow">
<xsl:apply-templates select="//table-wrap">
<xsl:with-param name="prefix" select="'column-wide-'" as="xs:string" tunnel="yes" />
</xsl:apply-templates>
</fo:flow>
</fo:page-sequence>
<fo:page-sequence master-reference="page-high">
<fo:flow flow-name="body" xsl:use-attribute-sets="fo:flow">
<xsl:apply-templates select="//table-wrap">
<xsl:with-param name="prefix" select="'page-high-'" as="xs:string" tunnel="yes" />
</xsl:apply-templates>
</fo:flow>
</fo:page-sequence>
</fo:root>
</xsl:template>The only template needed to override the default processing just stops bibliographic cross-references or references to supplemantary material generating a fo:basic-link just so there’s no warnings from the XSL formatter about unresolved cross-references:
<xsl:template match="xref[@ref-type = ('bibr', 'supplementary-material')]">
<xsl:apply-templates />
</xsl:template>The main stylesheet declares variables for the page width, margins, etc., so the same values are used in the main stylesheet to produce the final output and to work out whether graphics should be page-wide or column-wide and used in the ‘sizer’ stylesheet to set the pages’ dimensions.
As stated previously, the area tree for the ‘sizer’ document is saved as XML, and the filename of the area tree XML passed in to the main stylesheet, when run separately, as a parameter value. When the stylesheet comes to process a table-wrap, it looks up the dimensions of the table variants in the ‘sizer’ area tree and, based on the dimensions, decides which format of the table to use. Fig. 10 shows two of the tables from the previous ‘sizer’ document in the final formatted output.

Formatted pages
Current capabilities include automatic sizing of tables to be column-wide, page-wide, or page-high (either column-width or page-width), with manual overrides available to force a table to be page-wide or page high, plus automatic breaking of tables that are too high (or, for page-high tables, too wide) for the available space. When tables are broken into multiple subtables, each subtable gets its column widths from the ‘sizer’ table both so the subtables use the same widths and to avoid the automatic table algorithm optimising each subtable and leaving space at the bottom of a page.
A final ‘splitter’ stylesheets checks the area tree from the previous pass to ensure that all the floated figures and tables appear before the supplementary material, acknowledgments, and references. If the floats do overlap with this back-matter, the stylesheet splits the back-matter into a separate fo:page-sequence to prevent the overlap.
It wasn’t necessary to produce TIFF images of each table, but if it were required, the main stylesheet would output a separate FO document with individually-sized page dimensions for each table. Those FO documents would then be formatted to PDF or PostScript and then converted to TIFF using ImageMagick.
As shown in Fig. 11, all the top-level stylesheets use plos-xslfo.xsl (revised from jats-xslfo.xsl in the JATS Preview stylesheets) for basic formatting.
splitter.xsl does everything size-chooser.xsl does, and more, so it imports that file rather than importing plos-xslfo.xsl directly.
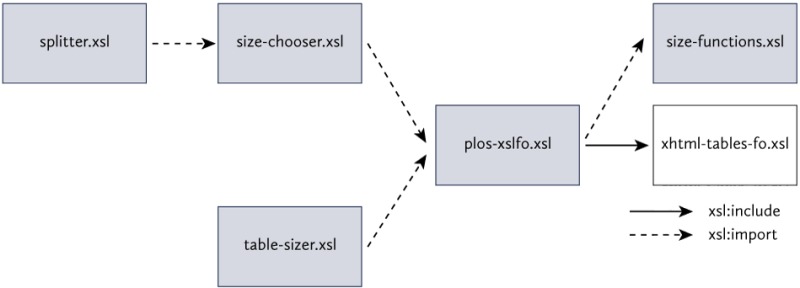
Imports in XSLT 2.0 customization
The original JATS Preview stylesheets for XSL-FO output was about 5,500 lines long, and the main stylesheet for processing PONE articles ended up about 5,300 lines long. Comparing with plos-xslfo.xsl, the two stylesheets shows 358 segments where the files differ, and of the unchanged segments, very few would be even 100 lines long.
The additional stylesheets for handling graphics, sizing tables and graphics, and determining whether and how to split large tables total about another 50% of the size of the core stylesheet.
No vendor extensions were used in the XSLT processing.
MathML was used for the equations and, as stated previously, the column-wide floats required a vendor extension since that is not part of XSL 1.1. Getting the column-wide floats to work reliably required bug fixes in several successive releases of the XSL-FO formatter before it could handle the input correctly, but as far as I know, at the time of this writing, there are currently no problems being experienced with the floats.
https://github.com/MenteaXML/xslt3testbed is a public, medium-sized XSLT 3.0 project where people could try out new XSLT 3.0 features on the transformations to (X)HTML(5) and XSL-FO that are what we do most often and, along the way, maybe come up with new design patterns for doing transformations using the higher-order functions, partial function application, and other goodies that XSLT 3.0 gives us.
There’s undoubtedly many things to try out, but a starter list of things to look at includes:
The project is ongoing, so this paper reports on work done to date.
The project started in October 2013, when XSLT 3.0 was sufficiently cooked that it could be used without the language changing drastically before Recommendation but not so hard-baked that it wouldn’t be possible for anything the project found making a change to the spec.
The generalisation about comments on W3C specs is that people don’t pay much attention to drafts until the spec is in Last Call or Candidate Recommendation stage, by which point it’s hard for a WG to make substantive changes.
XSLT 3.0 [[1]] was released as a Last Call Working Draft on 12 December 2013, so the timing was just about right.
The JATS Preview stylesheets made a good place to start since:
Results being worked towards include:
Possible results to not work towards or to actively work against include:
As of 10 March 2014, results include:
Developments after the conference will be reported on the GitHub project’s wiki [[2]] and/or my blog [[3]].
While not specifically designed for extension – or, perhaps, just explicitly not supporting new extension points – this paper has shown that the JATS Preview stylesheets make a good starting point for customized output using either XSLT 1.0 or XSLT 2.0. Customizing using XSLT 1.0 is worthwhile when you are (mostly) able to layer the customization over the functionality of the core stylesheets, whereas if you are making wholesale changes and extensions, it can be worthwhile to modify the stylesheets directly and, at the same time, change to using XSLT 2.0 for its features such as expressive power, concision, and stronger type checking.
Using XSLT 3.0 to process JATS at this point in time is more an experiment in using XSLT 3.0 than it is a viable strategy for using JATS in production, but participating in the XSLT 3.0 testbed project has benefits for the core JATS Preview stylesheets, the XSLT-related standards as they approach Recommendation status, and your own understanding of the new features of XSLT 3.0.
The XSL-FO vendor, Antenna House, has since produced a new 6.2 version with a completely new MathML module that did not exhibit this problem when I tested it.
All rights reserved.
The author grants the U.S. National Library of Medicine permission to archive and post a copy of this paper on the Journal Article Tag Suite Conference proceedings website.
Your browsing activity is empty.
Activity recording is turned off.
See more...